NTFS スパースファイル理解のための基礎知識
MFT の構造
NTFS にフォーマットされた Volume の最初には、MFT (Master File Table) という特殊領域が配置されています。この MFT には NTFS 全体管理に関する情報や、NTFS 内の全ファイル/全フォルダのエントリおよび属性情報を保有しています。Linux で言うところの i-node 領域です。
通常時はディスク空き容量の 12.5% が MFT 領域用として予約されています。
MFT には $ で始まるメタファイルの群と、各ファイル/フォルダのレコード(1KByte固定長)で構成されています。以下のような構造になっています。

各ファイル/フォルダの構造
前述の通り、NTFS ファイルシステム上の各ファイル/各フォルダのエントリーは、MFT 内に 1 KByte 長のレコードとして格納されます。
1 ファイルに 1 レコードです。Linux の XFS 等と同様、ディレクトリ(フォルダ)もファイルの 1 種と見なされます。
各レコードにはそのファイルに付随する属性情報が格納されます。属性の前にも $ が付きますが、メタファイルと混同してはいけません。
| Type | Attribute | Description |
| 0x10 | $STANDARD _INFORMATION | タイムスタンプやFlag(ファイルの種類)、USN等 |
| 0x20 | $ATTRIBUTE _LIST | MFT に入りきらなかった属性とその位置情報 |
| 0x30 | $FILE_NAME | ファイル名(もしくはフォルダ名) |
| 0x40 | $OBJECT_ID | ファイル識別子(Officeアプリ等で利用) |
| 0x80 | $DATA | ファイルに書き込まれた内容 |
| 0x50 | $SECURITY _DESCRIPTOR | 所有者やアクセス権情報 |
| 0xE0 | $EA | 拡張属性 (Extended Attributes) |
| 0x90 | $INDEX_ROOT | B+Tree の最上位ノードの位置を示す (フォルダで使われる属性) |
| 0xA0 | $INDEX _ALLOCATION | B+Tree の割り当て済 Index のリスト (フォルダで使われる属性) |
| 0xB0 | $BITMAP | B+Tree の Index の割り当て, 未割当を示す (フォルダで使われる属性) |
| 0xC0 | $REPARSE _POINT | Symbolic Link 等のリンク先を指定 |
Linux の XFS 等では "属性(メタ情報)" と "データ" は区別されますが、Windows の NTFS では "データ" ($DATA) も属性の 1 つに位置づけられます。
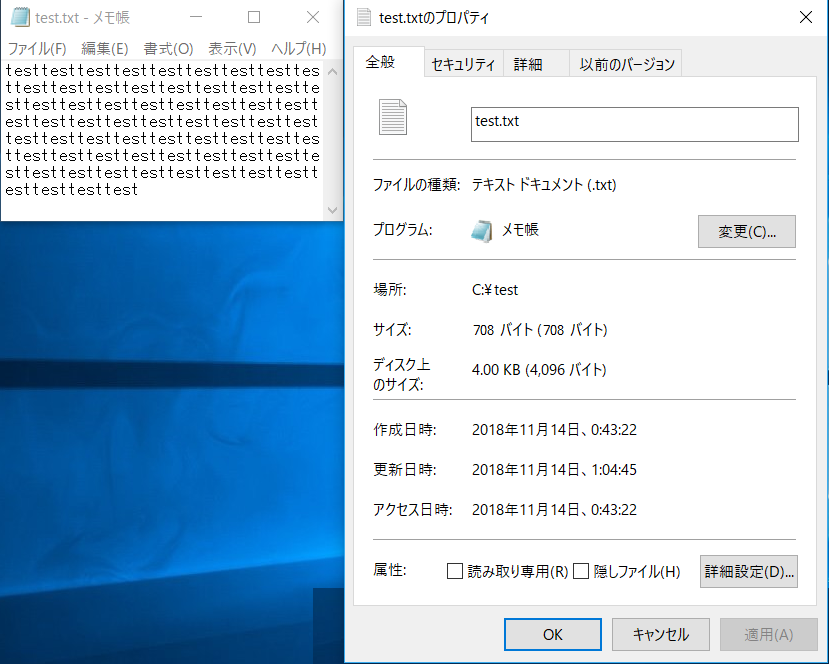
例えばメモ帳等のテキストエディタで "test" と書き込んで保存したファイル (test.txt) のデータ領域 ($DATA属性) には "test" という 4 文字が入り、4 Bytes のサイズになります。プロパティのサイズを確認すると 4 Bytes になっています。(Linux だと勝手に改行コードが入り、5 Bytes になりますが)

一般的なファイルでは例えば以下の 4 つの属性が含まれます。
- $STANDARD_INFORMATION
- $FILE_NAME
- $OBJECT_ID
- $DATA(フォルダの場合は $INDEX_ROOT, $INDEX_ALLOCATION, $BITMAP)
属性全体のサイズが 1 KByte を超えないうちは、全ての属性($DATA含む)を MFT 領域内に格納します。その結果、前述の test.txt の図のように「ディスク上のサイズ」は 0 byte になります。
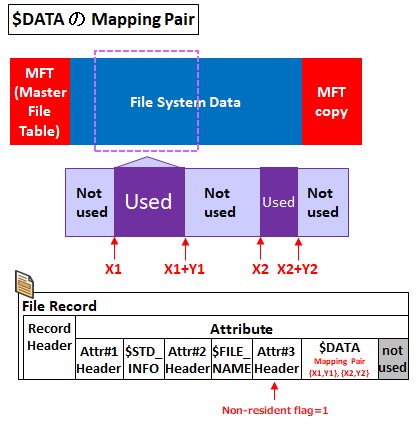
このサイズが大きくなり MFT に格納しきれなくなると、大きく育った属性の Attribute Header にある "Non-resident" フラグを 1 にした上で、属性値には "Mapping Pair" (Runlist とも呼ぶ) というパラメータを使って『File System Data』領域 ( ディスク上のサイズにカウントされる領域) に書き込んでいきます。
HDD へのアクセスは「クラスターサイズ(アロケーションユニットやブロックサイズとも言う。最近の一般的な PC では 4KB)」単位なので、データに文字列をどんどん追記していくと「ディスク上のサイズ」は 4 KBytes になります。例えば test.txt のデータ領域を 708 Bytes まで増やしてみると以下のようになりました。
このように MFT に入りきらないことを Non-resident と呼びます。(その対義語で、MFT内に入ることを Resident と呼びます。)
$DATA が MFT に入りきらない場合は前述の通り、MFT 内の $DATA 属性に "Mapping Pair" が格納されます。これは、$DATA の情報が『File System Data』領域のどのクラスタ範囲に格納するかを示しています。
具体的には { First Cluster (クラスタの開始位置)=X1, Cluster Count (クラスタ数)=Y1 } が格納され、クラスタの位置 X1 から X1+Y1 までの連続するクラスタに $DATA が格納されていることを示します。これは以下の図のように複数に分かれることもあります (フラグメンテーション) し、これがひどい場合はデフラグを実行しないとパフォーマンスが落ちます。
具体的にツールで見てみましょう。Active@ Disk Editor というフリーウェアをインストール、起動し、下図のように test.txt を選択した状態で「Inspect File Record」をクリックします。
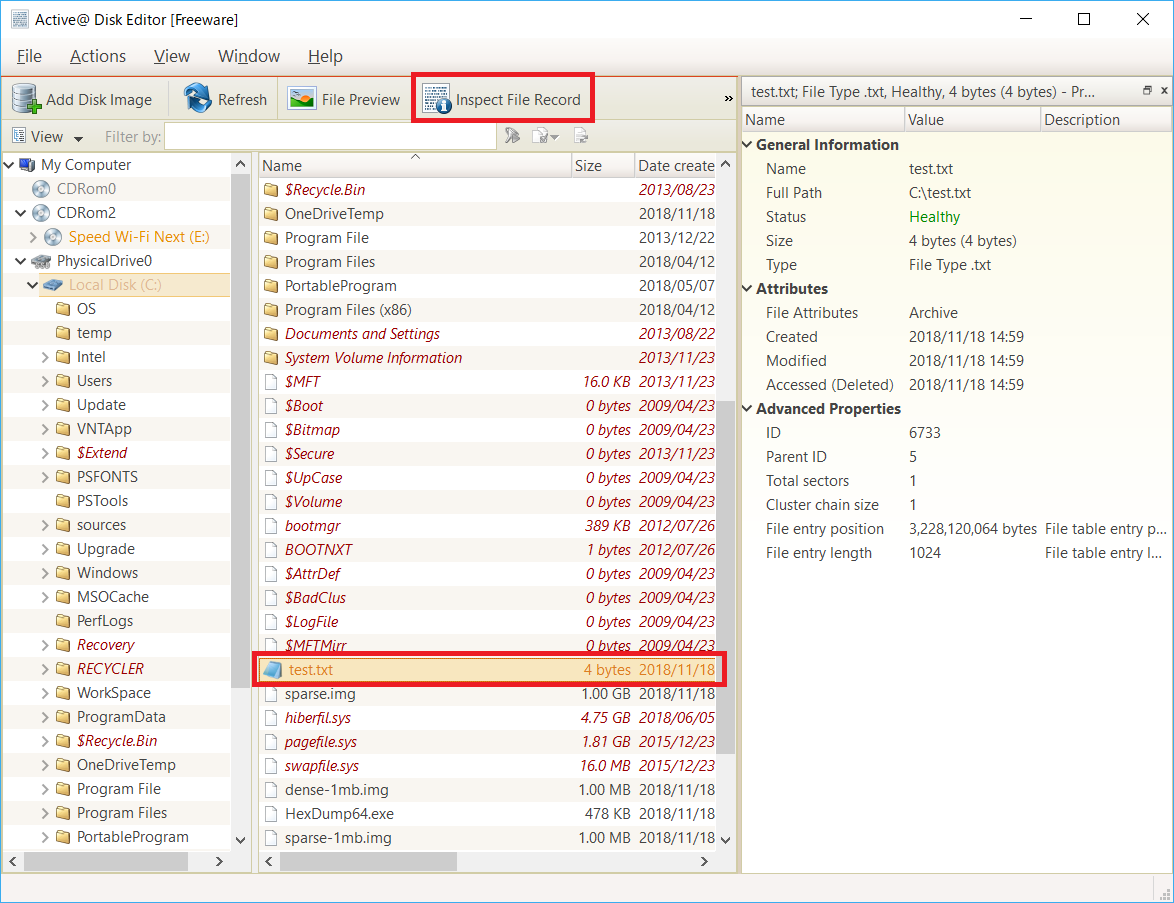
まずは 4 Bytes の状態では以下のように表示されます。
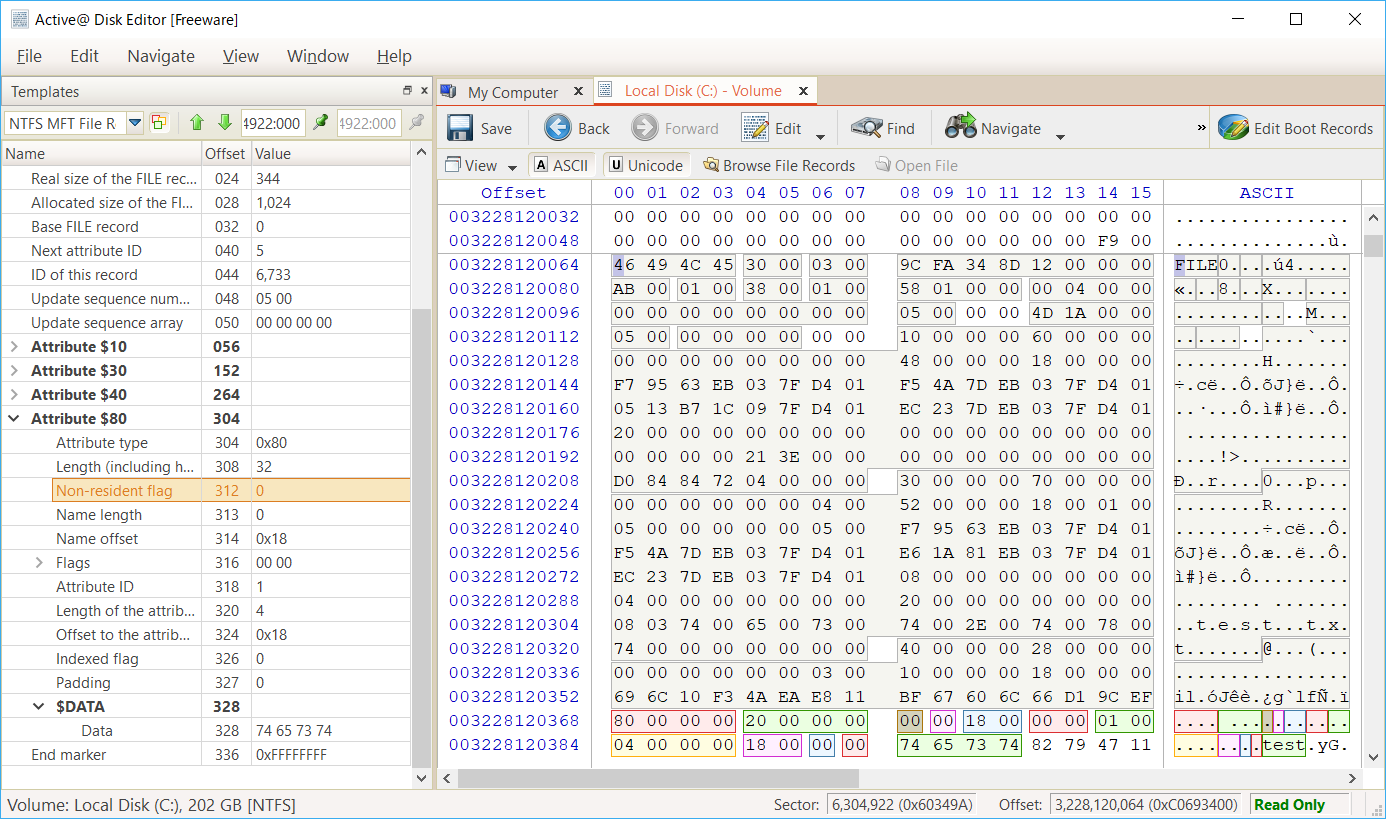
$DATA の属性ヘッダの Non resident flag が 0 で、$DATA の属性値として "test" という文字列が ASCII で格納されています。
次に、704 Bytes まで増やした場合は以下のようになります。
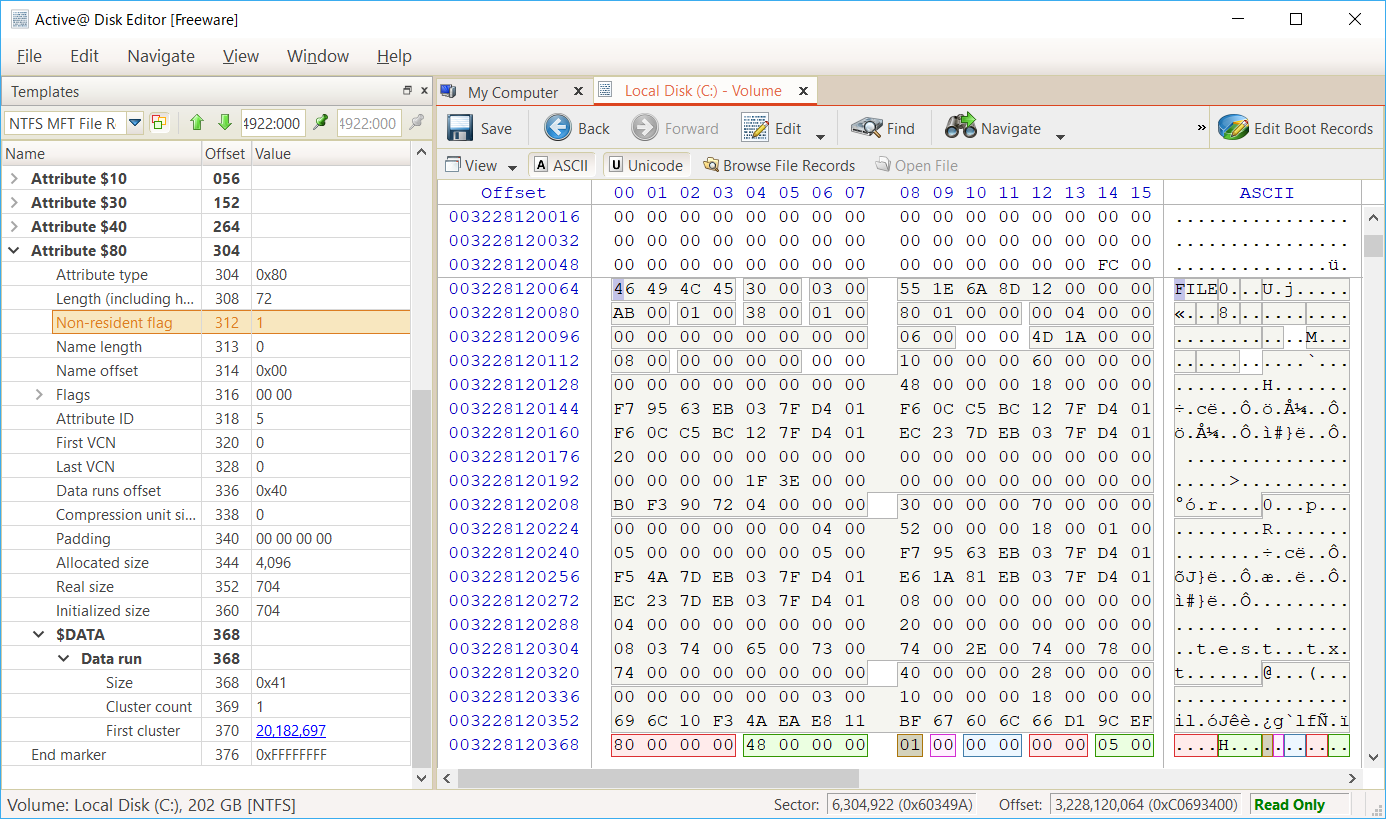
$DATA の属性ヘッダの "Non resident flag" が 1 となり、$DATA の属性値として "Mapping Pair" が格納されています。
Size が 0x41 となっています。これはややこしいのですが、4 が First Cluster (クラスタ位置) のサイズ (4 Bytes) を意味し、1 が Cluster count のサイズ (1 byte)を意味します。セクター開始位置が 20,182,697 という大きな値なので、4 Bytes のサイズが必要になる、という意味です。
Cluster count は 1 という値なので、1 byte だけ使っています。
スパースファイルの仕組み
スパースファイルは、ファイルのデータ空間において 0 がクラスター単位分(一般には 4KB )連続する領域には実施にはクラスタ (Linux では Block) を割り当てない、ストレージ節約術です。これはよく仮想サーバのイメージファイルで「Thin Provisioning(シンプロビジョニング)」として使われます。
例えば 100GB のイメージファイルを用意し、それを仮想マシンのHDD領域として使わせます。ですが仮想マシンは最初から 100GB も利用しないので、未利用領域は 0 の連続になります。この部分にクラスタを割り当てないようにするのです。
スパースファイルは$STANDARD_INFORMATION の属性値および $DATA の属性ヘッダに "Sparse Flag" を立てつつ、Mapping Pair を利用して実現します。
左が non sparse ファイル、右が sparse ファイルです。
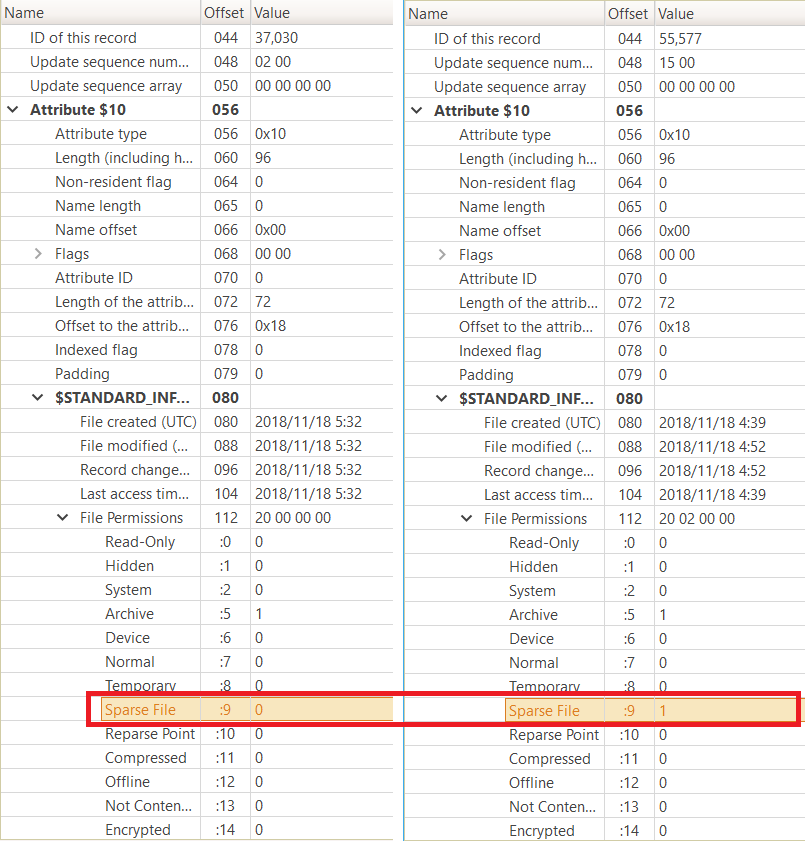

スパースファイルを作成してみる
実際に Windows でスパースファイルを作成してみます。まずは管理者権限でコマンドプロンプトを起動し、fsutil file createnew コマンドでファイルを作成します。
C:\>fsutil file createnew c:\sparse.img 1048576
ファイル c:\sparse.img が作成されましたfsutil コマンドで作られたファイルは 0 の連続で作られます。この状態ではまだ non-sparse です。プロパティを見るとこんな感じ。

この状態でファイルの属性情報を見てみます。
non-sparse (一般ファイル)の場合
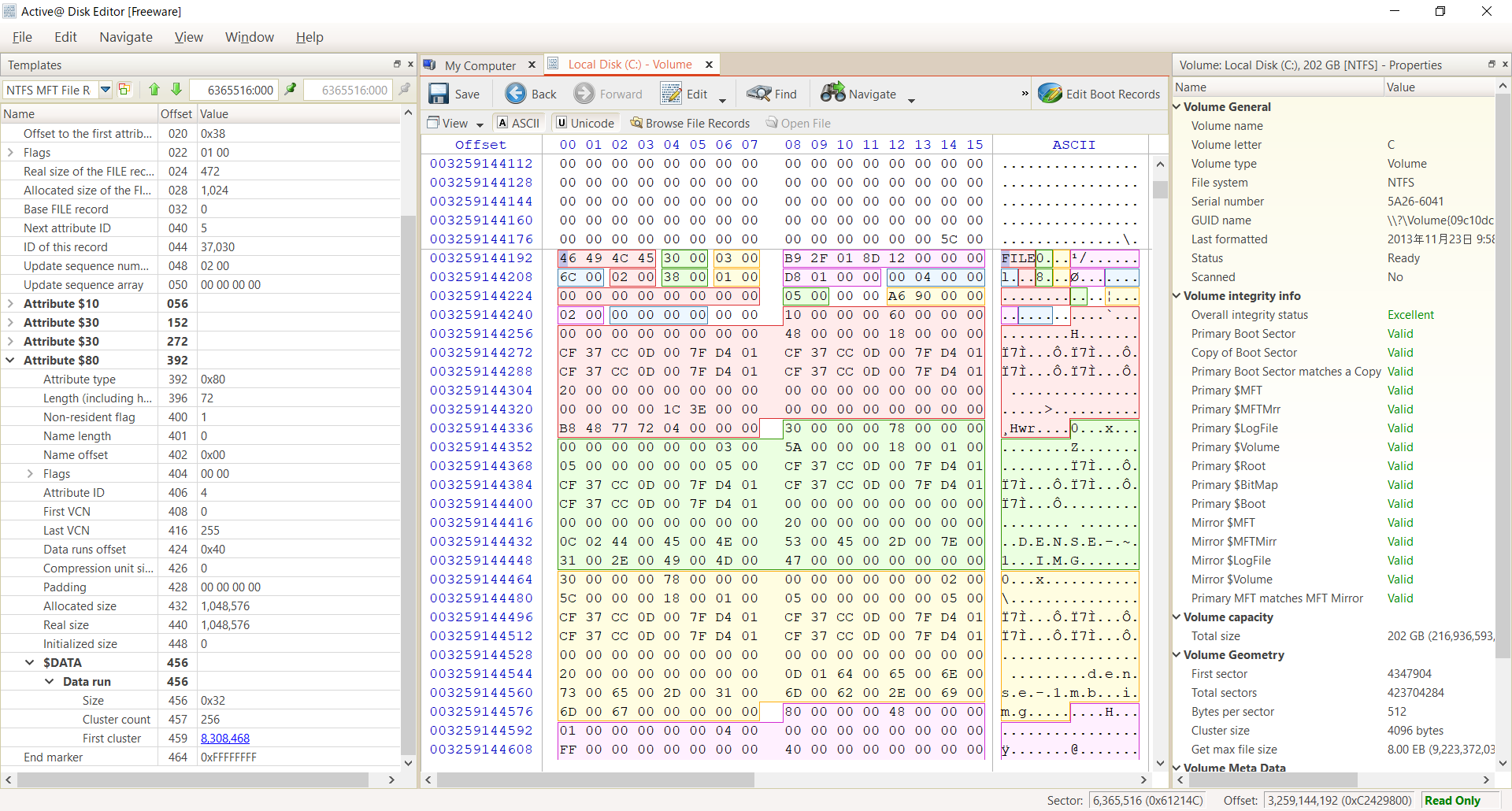
$DATA の Data run に Mapping Pair が格納されています。Non-Sparse では Size 0x32 のうち 3 が実際のクラスタの開始位置を示す "First Cluster" のサイズ数を意味しています。Size の 2 はそこから何個のクラスタを割り当てているかを示す "Cluster Count" のサイズ数です。
ここではクラスター# 8,308,468 から 256 個のクラスタが連続して、このファイルの領域として割り当てられています。1クラスタ当たりが 4KB なので 4 KB * 256個 = 1MB のファイルであることが分かります。
次に、これを以下の手順でスパースファイルにします。
C:\> fsutil sparse setflag c:\sparse.imgこれで前述の通り、$STANDARD_INFORMATION の属性値と $DATA の属性ヘッダの "Sparse" Flag に 1 が立ちます。ですがこの状態は "Sparse Ready" ではありますが、実際にはデータはスパースにはなっていません。次のコマンドでスパースにします。
C:\> fsutil sparse setrange c:\sparse.img 0 1048576sparse の場合
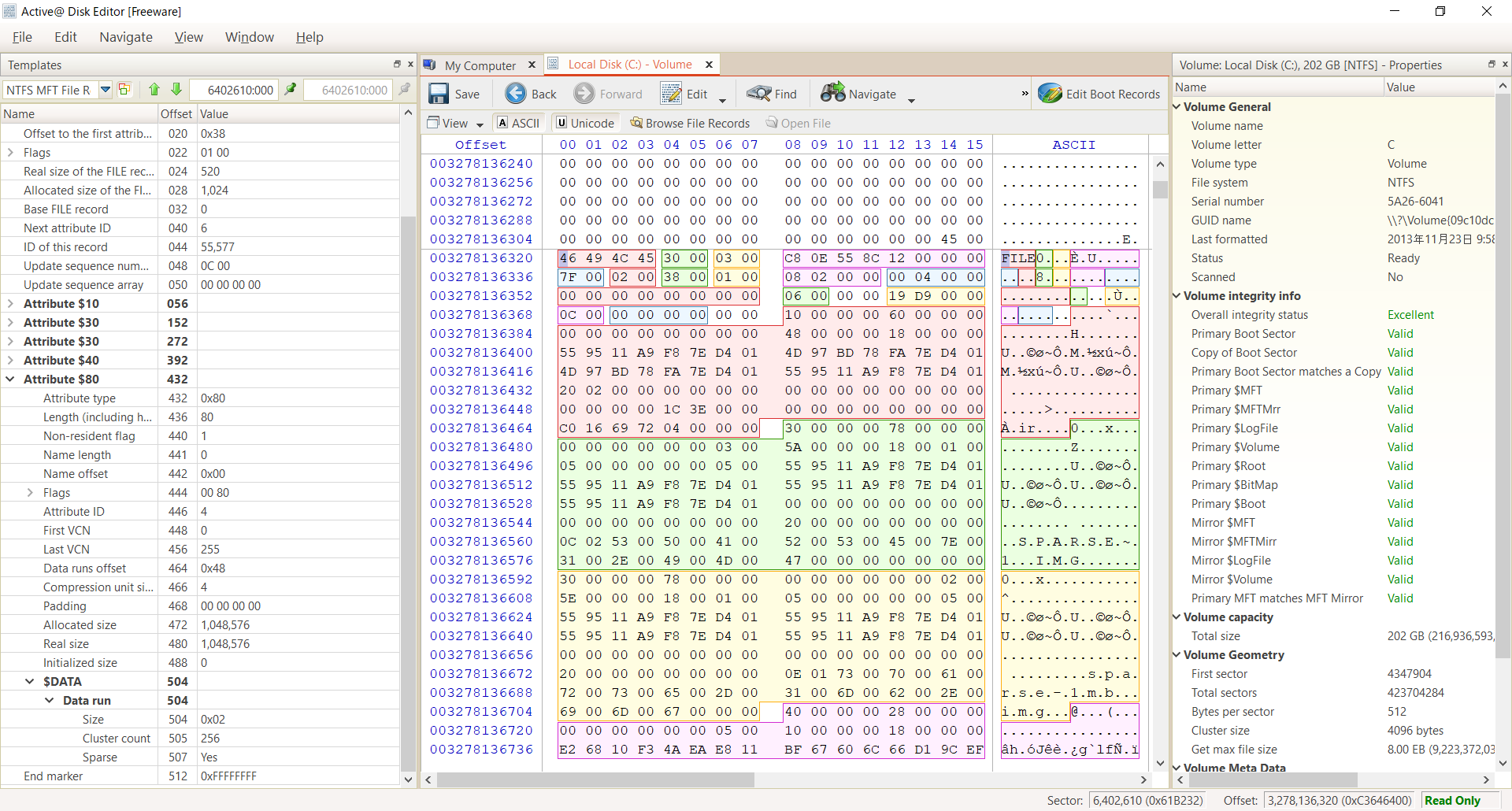
$DATA の Data run に Mapping Pair の Size 0x02 に注目して下さい。クラスタの開始位置のサイズが 0 になっています。これがファイルのデータ空間におけるスパースの開始を意味しています。Cluster Count は 256 なので 0 のクラスタが 256 個分広がるのです。
この結果、ファイルの「ディスク上のサイズ」は 0 byte になります。
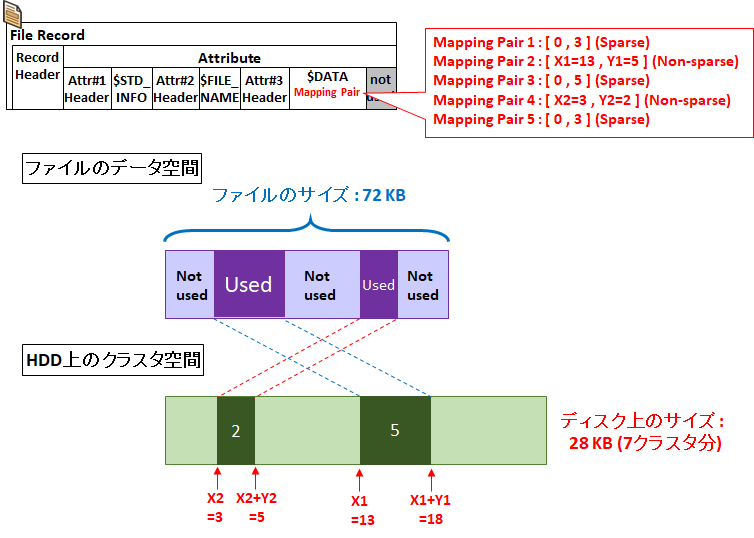
上のケースはそもそもファイルデータが全て 0 であったという特殊なケースですが、もう少し実践的なケースで考えてみましょう。
例えば以下のようなファイルを考えます。
- 最初の 12 KB (クラスタ 3 個分) が 0 の連続
- 続く 20 KB (クラスタ 5 個分) が 0 と 1 のランダム
- 次の 20 KB (クラスタ5 個分) が 0 の連続
- 次の 8 KB (クラスタ 2 個分) が 0 と 1 のランダム
- 最後の 12 KB (クラスタ 3 個分) が 0 の連続
このようなファイルは次の図のように表現されます。ファイルサイズが 72 KB ですが、実際に消費している HDD のクラスタは 7 個分 ( 28 KB ) になります。
【厳選 3 冊】Windows を学ぶための本



コメント