NTPとは
NTP とは、Network Time Protocol の略で、IP 機器が自動で時間を調整するために使うプロトコルです。
近年の IT 機器はシステム間で連携を取っていることが多いですが、ログの取得は各機器で取得するのが普通です。その際時刻がずれているとシステム連携のログの確認が困難となるため、この NTP で時刻同期を行うことは非常に重要です。
NTP では原子時計や GPS 等の高信頼性の時計自体を Stratum『0』と定義し、この時計と (ネットワーク越しではなく) 物理的に直結している NTP サーバが Stratum 『1』となります。Stratum『1』の NTP サーバを Primary サーバと呼びます。
この Primary サーバから NTP プロトコルを使って時刻同期する機器の Stratum は『2』となり、以降同様に NTP で時刻同期をとるたびに Stratum が『1』ずつ増えます。
この Stratum『2~15』の NTP サーバを Secondary サーバと呼びます。『16』以上は信頼できない時刻ソースとされ、利用できません (STP を手本としているようです)。
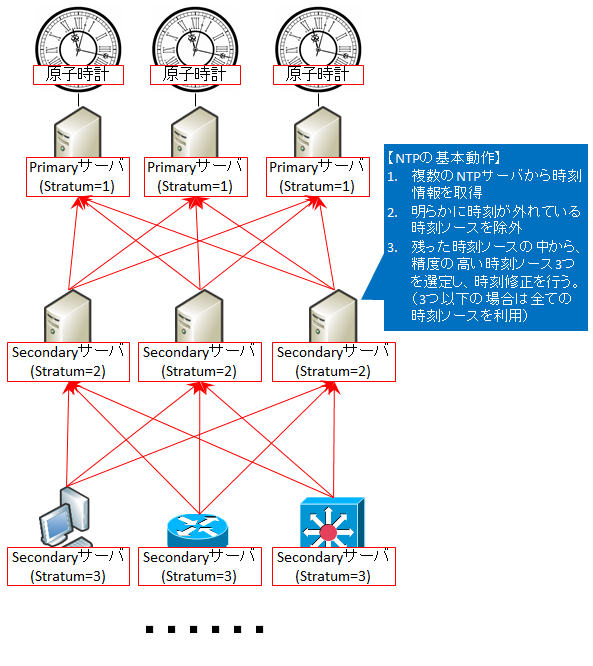
NTP の基本動作は、複数台の NTP サーバから時刻を取得し、まずは明らかに時刻の外れているものがあればそれを除外します。そして次に残った時刻ソースから、精度が高いと思われるものを 3 つ選び、それを使って時刻修正を行います (3 つ以下しか残っていない場合は全て使います)。(RFC5905 の 11.1. System Process Variables の "NMIN=3" がこれに該当)
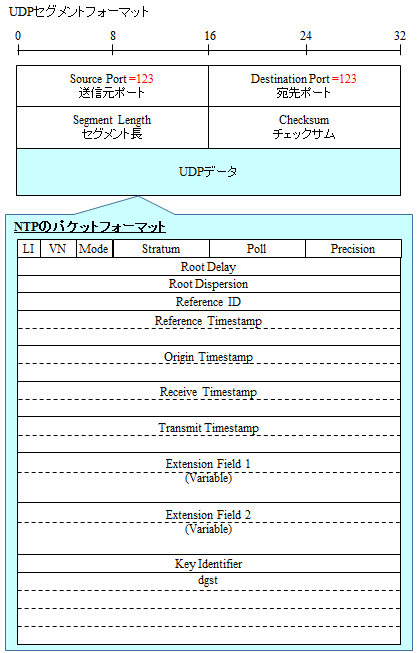
精度の高さは Distance とも呼ばれ、NTP パケットにある Root Delay と Root Dispersion (2 つとも後述します) から計算されます。
実装として Stratum (階層) を加味することもあります。(Linux の chrony の実装)
NTPのパケットのシーケンス
NTP は、『サーバからもらった時刻をそのまま設定する』という単純なプロトコルではありません。
パケットのやり取りの中で、サーバの処理遅延や NW 遅延、NW のゆらぎ (Jitter) の統計を取り、精度の高い時刻を計算します。
NTP パケットの中には Timestamp が 4 つありますが、時刻計算に使われるのはそのうち以下の 3 つです。
- Origin Timestamp
- Receive Timestamp
- Transmit Timestamp
上記のパケットの中身の Timestamp に加え、パケットが到着した時間を『Destinaion Timestamp』として内部で保持し、これら 4 つの Timestamp を使って時刻計算を行います。
具体的には、NTP クライアント/サーバ、または NTP Peer は、Timestamp について以下のようなやり取りを行います。
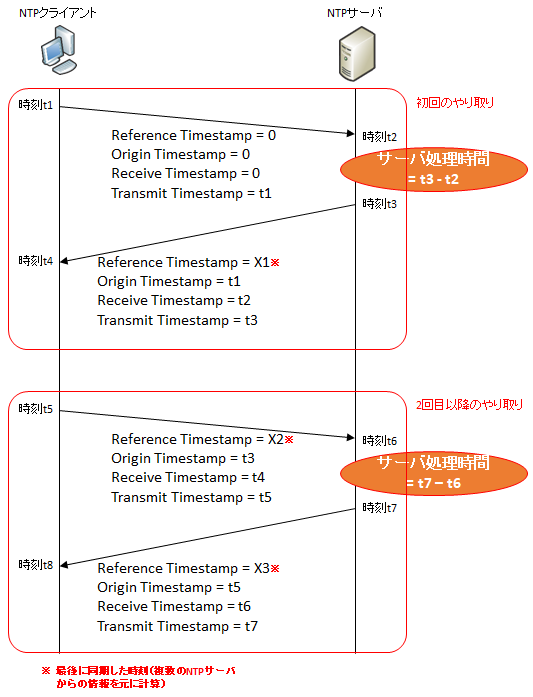
NTP クライアントはタイムスタンプから以下の統計情報を計算します。
RTT (往復時間) = ( t2 - t1 ) + ( t4 - t3 )
注意点としては、そもそもの目的は時刻同期ですので、『NTP クライアントと NTP サーバで基準となる時間がずれている』ことが前提です。なので
と置き換えたほうが分かりやすいかもしれません。(ある基準時刻"T" の NTP クライアントの時刻情報を Tcl , NTP サーバの時刻情報を Tsv とします)
NW 遅延が行きと帰りで同じと仮定すれば t2' - t1' = t4' - t3' ですので、Offset = Tsv - Tcl となるわけです。
一方 RTT は、NTP クライアントが送信してから戻ってくるまでの時間から、NTP サーバの処理時間を省いたものです。これも先程の代入を行うと
となり、今度は Tsv や Tcl が消えますので、クライアントサーバ間の時刻差の影響が消えます。サーバ処理時間はタイムスタンプから簡単に計算できるので、予測するしかない NW 遅延部分のみを抽出しています。
この RTT 自体は NTP クライアントと NTP サーバの距離を表しており、この距離が遠い程、NTP 時刻同期の精度が悪くなります。
また、この RTT 値が毎回同じような値であれば NW 遅延は安定しており、すなわち Offset の計算も精度が高くなります。しかし毎回かけ離れていると、それは NW 遅延が t2' -t1' = t4' - t3' の仮定が怪しくなり、Offset の計算精度も疑わしくなります。
なので NTP では、Primary サーバまでの NW 遅延を表す Root Delay、Primary サーバまでの NW 遅延の揺らぎを表す Root Dispersion を計算し、それを NTP パケットの中に格納し、下位 NTP クライアントに伝搬します。
NTP クライアントはその情報を使って時刻ソース選定を行うとともに、もし自身よりさらに下位のサーバがいるときはその Root Delay および Root Dispersion を再計算(自身の計算した RTT を加味)し、さらに伝搬していきます。
NTPのアソシエーションモード
アソシエーションとは、NTP の時刻情報を提供する形態を示したものです。アソシエーションモードには以下の 6 種類があります。
- Symmetric Active
- Symmetric Passive
- Client
- Server
- Broadcast
- Broadcast Client
NTP パケットの Mode は、RFC 上は相手のアソシエーションモードを想定してセットするとあるのですが、Windows, Linux, Cisco どの実装を見ても、自分のアソシエーションモードをパケットに含めて送信しています。つまり、自分が Symmetric Active であれば Mode=1 , Symmetric Passive であれば Mode=2 , Client であれば Mode=3 , ...となっています。
Association Mode = 1~4の場合のパケットやり取りを以下に図示します。
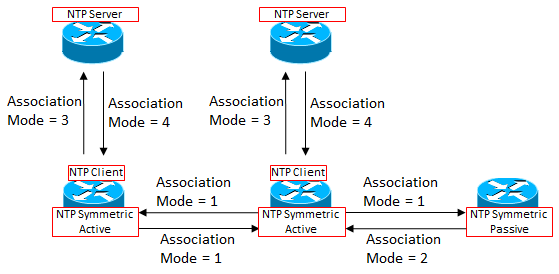
Symmetric Active 同士
Symmetric は Peer とも呼ばれます。
このアソシエーションでは、Stratum が同じもの同士の場合は、どちらがクライアント、サーバになるということはなく、互いの時刻情報を信頼し合い、互いを時刻の修正のためのソースとして利用します。
Stratum が違う場合は、値が大きいほうが小さいほうの時刻情報を信頼し、時刻修正のためのソースとして利用されます。
ただしこれは、他に信頼性のある NTP サーバからも時刻情報を取得していることを前提とした、バックアップ用途であるケースがほとんどです。
Active は常に相手と同期を取るよう自発的に NTP パケット (Mode=1) を相手に送信します。
Symmetric ActiveとSymmetric Passive
基本的には Symmetric Active 同士と同じ動きですが、Symmetric Passive のノードは自分からは NTP パケットを送りません。
Active の相手が送ってきたのをトリガーに、NTP パケット (Mode=2) を送り返す、という動作をします。
なお、Cisco ではデフォルトで Symmetric Passive モードが有効になっていますので、悪意ある第 3 者から、時間のずれた Stratum 1 の Symmetric Active パケットを受けると容易に時刻ずれを引き起こしてしまいますので、基本は認証キーを使うことを覚えておきましょう。
ServerとClient
一番実装の多いアソシエーションです。
Client は Server に対し NTP パケット (Mode=3) を送信し、それを受けた NTP サーバは Client に対し NTP パケット (Mode=4) を返します。
Client は Server から受信した Timestamp を元に、時刻同期を行います。
プロトコル上、Server も Client から Timestamp を受け取りますが、時刻同期は行いません。
前述の通り、Server から Client への送信時刻や受信時刻等の Timestamp 情報は、Client が時刻差, RTT, およびジッターを推測し、受信した時刻を補正し精度を高めるために使われます。
なお、Symmetric のアソシエーションも同様に、相手からの Timestamp 情報を元に補正をかけ精度を高めています。
Broadcast ServerとBroadcast Client
Broadcast Server は同セグメント内に Broadcast Client が居ることを想定し、NTP パケットをブロードキャストします。Broadcast Client はこれを受信し、時刻同期します。
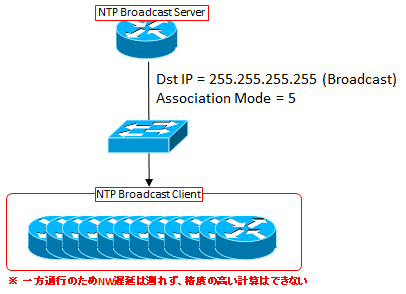
なお、他のアソシエーションでは、互いにやり取りする NTP パケットの中にある送信時刻や受信時刻等からネットワーク遅延等を計算し、それを補正するため高精度になりますが、このアソシエーションではパケットは一方的に受けるのみなのでその計算ができず、精度は低くなります。
精度は少し粗くてもいいから同セグメント内のクライアントに一遍に送信したい、というケースには最適です。
NTPサーバを2台指定する場合の注意点
前述していますが、RFC で規定されている NTP の動きとしては、以下のようになります。
- NTP クライアントは複数の NTP サーバから時刻情報を取得
- 取得した時刻情報の中から、明らかに時刻が外れたもの (falsetickerと呼びます) を除外 (Selection Algorithm = Byzantine fault detection principles)
- 残った NTP サーバ (truechimer と呼びます) が 4 つ以上の場合、それらの中から精度の高い時刻ソースを 3 つ選定し、尤もらしい時刻を算出 (Combine Algorithm)。
この動作から分かる通り、NTP クライアントが NTP サーバとして 2 台指定した場合、その 2 つがかけ離れた時刻になっている場合は時刻同期ができません。
なので NTP サーバを複数台指定する場合は 3 台以上 (RedHat などは 4 台) が推奨されています。
もし NTP サーバを 2 台指定するのであれば、prefer や trust 等のオプションを使うと良いでしょう。
Ciscoの場合
(config)# ntp server ntp1.jst.mfeed.ad.jp prefer (config)# ntp server ntp2.jst.mfeed.ad.jp
(config)# ntp peer ntp1.jst.mfeed.ad.jp prefer (config)# ntp peer ntp2.jst.mfeed.ad.jp
上記のように設定した場合、2 台とも近い時刻であれば 2 台の平均を取り、もしかけ離れた時刻であれば、ntp1 のみを使って時刻同期を行います。
Linux の chrony の場合も同じように prefer オプションが使えますが、trust というオプションもあります。
Linuxのchrony.confの場合
server ntp1.jst.mfeed.ad.jp trust # preferも利用可 server ntp2.jst.mfeed.ad.jp
この設定は単純に基本は ntp1 を使い続け、もし ntp1 が故障等で接続できなくなった場合に、ntp2 を使って時刻同期を行う、という設定になります。
NTPのバージョンとそれぞれの違い
現在は NTP バージョン 4 (RFC5905) です。バージョン 2 および 3 と互換性があります。
NTP v2 から v3 で変わったことと言えば、主に認証機能が付いたことです。では NTP v3 と v4 の違いは何でしょうか。
簡単に言うと大きく以下の 3 つです。
- 『Expanded NTP timestamp』により、扱える時間の精度を 1 ナノ秒以下にすることができた
- 『clock discipline algorithm』により、ハードウェアに内在している『どのくらいの度合いで時刻がズレるかの傾向』(つまりドリフト) の精度を上げることができた
- 1 および 2 により、頻繁に時刻同期しなくてもよくなったので、最大同期間隔を 1024 秒から 36 時間まで引き上げた
RFC5905 には以下のように書かれています。
The NTPv4 design overcomes significant shortcomings in the NTPv3
design, corrects certain bugs, and incorporates new features. In
particular, expanded NTP timestamp definitions encourage the use of the floating double data type throughout the implementation. As a result, the time resolution is better than one nanosecond, and
frequency resolution is less than one nanosecond per second.
Additional improvements include a new clock discipline algorithm that is more responsive to system clock hardware frequency fluctuations.
Typical primary servers using modern machines are precise within a
few tens of microseconds. Typical secondary servers and clients on
fast LANs are within a few hundred microseconds with poll intervals
up to 1024 seconds, which was the maximum with NTPv3. With NTPv4, servers and clients are precise within a few tens of milliseconds with poll intervals up to 36 hours.
【日本語訳】
最新のマシンを使った典型的な Primary サーバは数十マイクロ秒以内の精度である。高速の LAN にある典型的な Secondary サーバやクライアントは数百マイクロ秒の精度であり、これは最大 1024 秒の間隔で同期している。この 1024 秒は NTPv3 の上限値である。NTPv4 では同期間隔の最大値を 36 時間まで引き上げている。
コメント
たまたまOpenNTPDをあれこれ調べていましたので、興味深く拝読しました。
で、OpenNTPDをWindows10 + VMWare + (OpenBSD | Debian) な環境で使うと
不可解な挙動を確認しました。
純粋なDebian機 + OpenNTPDでは、今の所問題無し。
お暇でしたら、何らかの追試をして頂くと嬉しいです。
詳細は下記URL中 2020-03-07, 2020-03-11付けの記事で駄文を書いて
います。
今後共宜しくお願い致します。
> sakaeさん
コメントありがとうございます。
お返事が遅くなり申し訳ありません。。現在本業が炎上中で、なかなか時間が取れない状況でございます。貴サイトをちらっっとだけ拝見させて頂きました。
完全な推測ですが、ntpではHWクロックのずれを修正することも見込んでいる(drift)ので、仮想化特有の問題なのかな、と感じました。(根拠は無いです)
あまり中身の無い返信ですが。。。今後もぜひ宜しくお願い致します。
もう、見ていないと思いますが…
OS上での時刻は、HWクロック(水晶発振器)を分周した形で、時刻を刻んでいます。
しかしながら、VMwareでは、HWクロック(=CPUが動作するためのクロック)は、
ソフト的に供給されており、物理的なクロック(水晶発振器)からの供給ではありません。
このため、他のアプリケーションの負荷が高い場合は、OSのタスク切り替え機能により
VMwareにCPUクロック割り当てができなくなります。
しかしながら、ゲストOSは物理的なクロック(水晶発振器)からクロック供給を受けている前提で動作しているため、負荷変動によるクロック抜けを検知できず時刻遅れが生じます。
また、
ntpの精度向上のために設けられた drift ファイルですが、平常時のクロック供給状況に応じて修正されますが、高負荷状態が発生した場合には、クロック抜けが発生してるにもかかわらず、平常時の時刻補正をしてしまうため、時刻ずれを大きくしてしまう原因の1つになってしまいます。
VMware Player/VMware Workstation 等のホストOS型仮想環境を使用している場合は、おおよそ遅れが大きくなる事象が発生しますが、
VMware vSphere(ESXi)でvmotion等のホストの変更をすると、ホストごとに水晶発振器のクセ(drift値)が異なりますが、ゲストOSはホストが変わったことを知らずに、drift値
をそのまま使用するため、移動元や移動先のホストのクセにより、時刻が進んだり、遅れたりする事象が発生します。