前提
はじめに文字コード、ASCII コードについて知っていると理解が進むと思いますので必要に応じて下記もご参照下さい。
バイナリデータとテキストデータの判別
バイナリ形式 (バイナリデータ) とは、0 と 1 の羅列により主にコンピュータが理解するために記述されたデータ形式のことです。
1 bit で意味を成すもの (いわゆる Flag) や、2 Byte で 0 から 65535 までの数値により何かの大きさを示すもの、はたまた数 KB ~ 数 MB で位置と色により画像を表現するものなど、アプリケーションによって定義や扱いが決まっています (アプリ作成者の設計によって決まります)。
一方、テキスト形式 (テキストデータ) とは、0 と 1 が羅列していることには変わりありませんが、「文字コード」に従って書かれている、主に人間にも理解しやすいように記述されたデータ形式のことです。
一般に 1 Byte や複数 Bytes 単位で特定の 1 文字を表現し、その文字の定義は規格によって決まっているため、アプリケーションによって解釈が変わることはありません。

上図のように、同じビット列であっても、アプリ次第でバイナリ形式のビット列として扱われることもありますし、テキスト形式の文字列として扱われることもあります。
つまり、bit 列からはバイナリデータかテキストデータかの判別はできません。
テキストデータは「テキストエディタ」に分類されるアプリで読み込む際は必ずテキスト形式として文字コードに従って読み込まれ、文字列としてディスプレイに表示されます。そしてキーボードで入力した文字列は文字コードに従って 0 1 のビット列に変換され、やがてファイルに保存されます。
なので強いていえば、テキストエディタで色々な文字コードとしてファイルを開いてみて、意味の通じる文字列になればテキストファイルです。
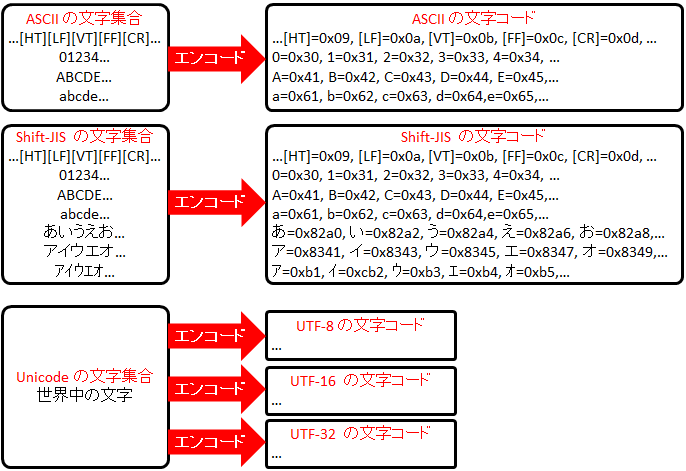
ASCII コードとマルチバイト文字コード
文字コードの 1 つである「ASCII コード」のみで書かれたテキスト形式を特に「ASCII 形式」と呼びます。
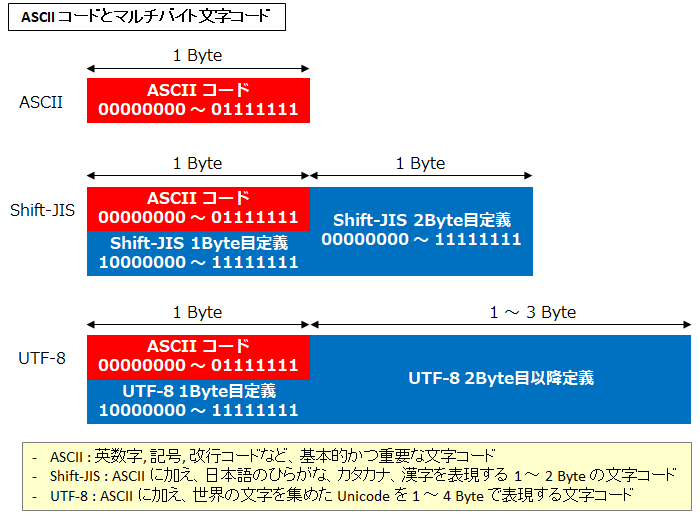
ASCII コードというのは平たく言うと英数字や記号 (@#$%& 等) 等の英語圏でよく使われる文字を表現するコードのことで、世界的に極めて基本的かつ重要な文字コードです。1 文字あたり必ず 1 Byte になる (7 bit で表現され、先頭 1 bit は常に 0) ため、シングルバイト文字コードとも呼ばれます。
一方、日本語の文字 (ひらがな、カタカナ、漢字など) などは UTF-8 や Shift-JIS といった文字コードが使われ、複数バイトで表現されるため、マルチバイト文字コードと呼ばれます。ただし、多くのマルチバイト文字コードは、ASCII コードと下位互換があります。(先頭 bit が 0 のときは ASCII と判断)
バイナリとテキストの比較
一般にバイナリ形式のファイルを「バイナリファイル」、テキスト形式のファイルを「テキストファイル」と呼びますが、バイナリとテキストの区分けはファイルだけでなく、ネットワークプロトコルにも適用できます。
ネットワークプロトコルの場合は特に「バイナリ」「テキスト」という分類よりも「バイナリ」「ASCII」という分類で考えるケースが多いです。(この辺りは後述します。)
以下にバイナリとテキストの比較を示します。
| 形式 | バイナリ | テキスト |
|---|---|---|
| 概要 | - コンピュータが理解しやすい形式 - Binary Editorで開くと 0 と 1 の 羅列が表示される | - 人間が理解しやすい形式 - Text Editorで開くと文章が表示される |
| 意味を成す 構成要素 | - 0 or 1 の羅列 - 定義や扱いはアプリによって変わる | - 文字列 - 定義は不変 (文字コードの規約に従う) |
| ファイル | [バイナリファイルの例] .exe (実行可能ファイル) .docx .dat (アプリが読み込むデータ) | [テキストファイルの例] .txt .html / .css .ldif (ldap の記述方式) .c / .h (C 言語ソースコード) |
| NWプロト コル | [バイナリ形式のNWプロトコルの例] - NTP - RIP / OSPF / BGP | [アスキー形式のNWプロトコルの例] - http v1.0 v1.1 - SMTP - telnet - FTP Control (データ転送はバイナリ) - LDAP (一部バイナリを含む) |
テキストエディタとバイナリエディタ
テキストエディタ
テキストファイルはメモ帳などのテキストエディタで開くことで内容を人間が確認することができます。そして一般にはキーボードを通じて入力や編集が可能です。
バイナリファイルもテキストエディタで開くことはできますが、文字コードで定義されていない場合はスペースや中点・などに置き換わるためデータとして不完全ですし、コンピュータやアプリが扱うデータであるため取り扱いが困難です。
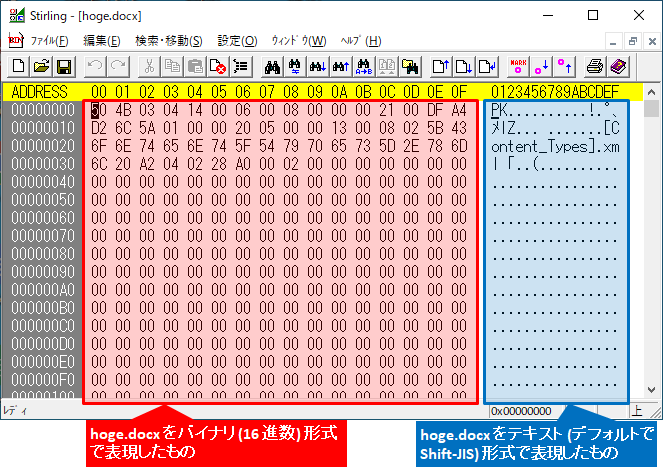
以下にバイナリファイルである .docx をテキストエディタ (sakura エディタ) で開いた時の例を示します。

バイナリエディタ
一方、バイナリファイルは stirling などのバイナリエディタで開くことで、0 と 1 の羅列を確実に確認することができます。そして 0 を 1 に、または 1 を 0 に修正することも可能です。
ただし、当然ながら「何ビット目が 0 の場合はどのような意味があり、1 の場合はどのような意味があり、、、」というのを人間が理解していないと、内容の確認や修正をすることができません。
また、テキストファイルをバイナリエディタで開くこともできますが、テキストエディタと比べて特に大きな効果はありません。バイナリエディタでも大抵は別枠で ASCII やマルチバイト文字コード (Shift-JIS や UTF-8) も一緒に表示されます。stirling の場合は右側に表示されています。
先ほどの .docx ファイルをバイナリエディタ (Stirling) で開いた時の例を以下に示します。
一般的には「実行可能ではないバイナリファイル」は専用のアプリケーションが存在し、専用のアプリケーションがそのファイルを開き、そして人間に分かりやすい形式 (ここではテキスト形式への変換はもちろん、マトリクス表などの表示を含む) に変換して表示してくれます。
バイナリ=exe?OSでの取り扱い
文脈によっては「実行可能ファイル」(.exe など) のことをバイナリと呼ぶことがあります。
例えば Linux では /bin というフォルダに ls や cat などのコマンド (実行可能ファイル) が保存されていますが、bin というのはバイナリ (binary) を意味しています。
OS は「実行可能ファイル」を実行 (例えば Windows なら .exe のファイルをダブルクリック) するとそれをプログラムとしてメモリに展開します。
一方、Windows にて hoge.txt というテキストファイルをダブルクリックするとメモ帳 (notepad.exe) がプログラムとしてメモリに展開され、そのプログラムが hoge.txt を読み込み、その中身を表示します。
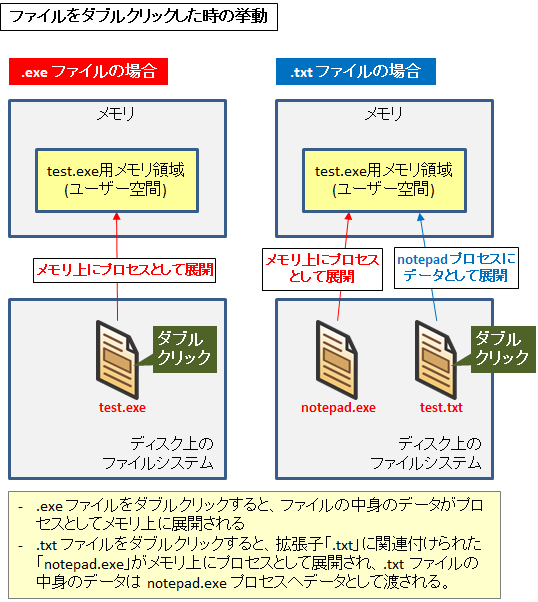
これらは拡張子によって起動すべきアプリケーションが定義づけられているからです。
つまり .txt はメモ帳で開く、.xlsx はエクセルで開く, .html はブラウザで開く、といった定義です。
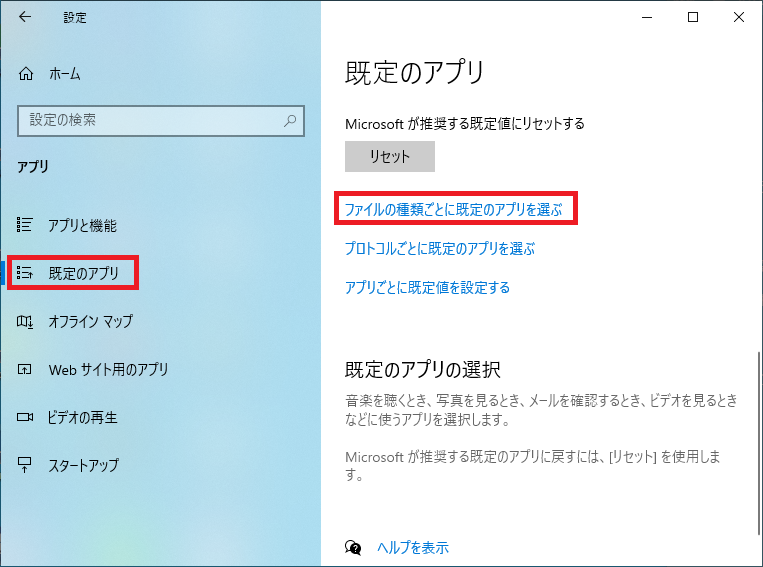
なお、この関連付けは Windows の「設定」の「既定のアプリ」の下部にある「ファイルの種類ごとに既定のアプリを選ぶ」にて設定されています。
ソースコードとスクリプト
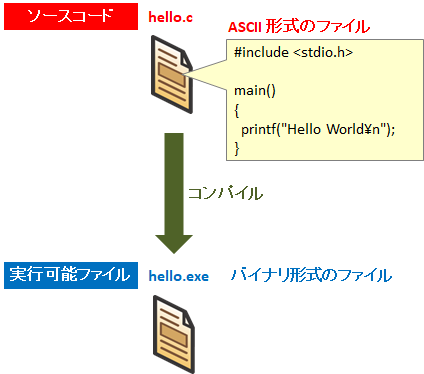
プログラム言語のソースコードやスクリプト言語のスクリプトは、一般に ASCII コードで書かれます。これはプログラムやスクリプトを作成したり扱うのが人間だからです。人間が理解しやすいように ASCII コードが使われます。
C 言語などのプログラム言語の場合は「コンパイル」という処理によって「テキストファイルのソースコード」を「実行可能なバイナリファイル」に変換します。これによりコンピュータが理解しやすい「機械語」に翻訳されるわけです。
PHP 等のスクリプト言語の場合は、そのスクリプトの文字列を「インタープリタ」と呼ばれるプログラムに渡し、インタープリタがスクリプトの内容を機械語に翻訳し、処理をさせるわけです。
ネットワークプロトコルのバイナリ形式,テキスト形式
[HTTP v1.0] / [HTTP v1.1] / [SMTP] 等は ASCII コードだけで通信することが規格で定められています。
このようなプロトコルは telnet コマンドで通信できたりします。
以下の動画では telnet を使って http 通信をしています。
以下の記事でももう少し詳細を記載しています。
SMTP や FTP Control (制御チャネル : tcp/21) の通信も Telnet コマンドとキーボードを使って通信をすることができます。
ところで、http はもともと ASCII 形式の html ファイルをダウンロードすることを主目的としていました。
メールを扱う SMTP も同じく、ASCII 文字を送る規格として生まれました。
そのため、当時は http や SMTP では ASCII コードのみ送受信が可能でした。
ですがこれではあまりに不便なので、MIME (読み方 : まいむ) という規格によってマルチバイト文字やバイナリを扱う手段を設けました。
具体的には、以下の手段が取られます。
- ヘッダに Content-Type フィールドを加えることにより、ファイルのデータ形式を相手に通知し、ASCII ではなくバイナリであることを受信側に理解させる
- ヘッダに Content-Transfer-Encoding を加えることにより、マルチバイト文字、バイナリ形式データを Base-64 や qp (Quoted Printable) といったエンコード方式により ASCII 形式に変換する (受信側で再び元に戻す)
では、以上を踏まえ、wireshark で http 通信のパケットキャプチャを見てみましょう。
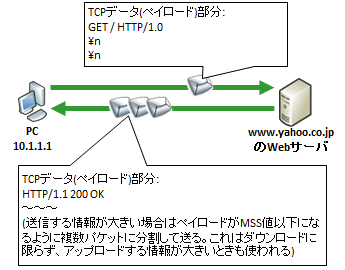
以下は test.gif という画像ファイルを http でリクエストするパケットのキャプチャです。

上部のオレンジ枠は Ethernet や IP, TCP ヘッダの情報のサマリが表示されています。中央の緑枠には http パケットの中身が分かりやすく表示されています。
そして下部は http レイヤーのデータをバイナリ形式と ASCII 形式で表示しています。
Wireshark でもバイナリエディタと似たように、左側にバイナリ、右側に ASCII が表示されています。
ASCII で GET (47 45 54) という文字列が見えます。つまり GET メソッドは ASCII 形式でパケット上を流れています。
次に、このリクエストに対する http レスポンスのパケットキャプチャを見てみましょう。
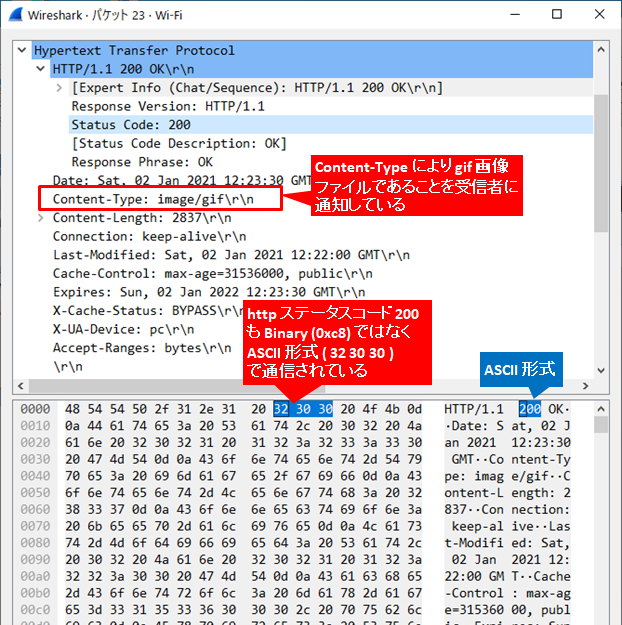
http ステータスコードの 200 さえ、16 進数ではなく ASCII で表現されています。
では gif のデータ転送はどうなっているかというと、以下のようにバイナリで通信されています。
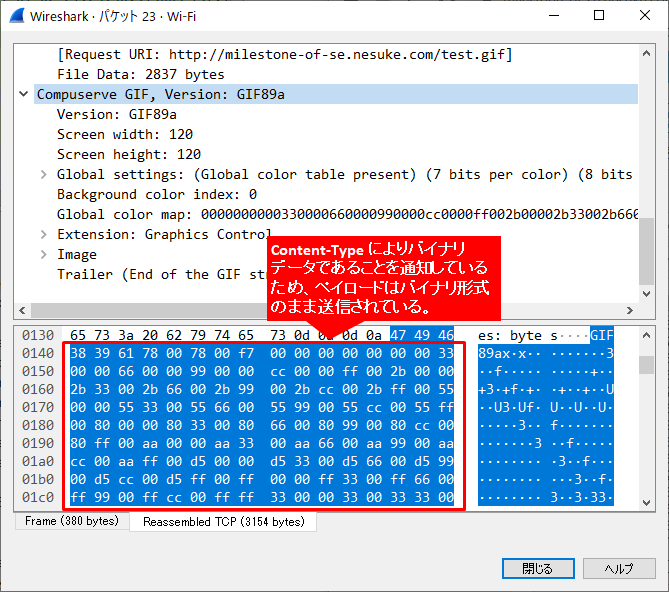
なお、メール (SMTP) だと Base64 や qp によりエンコードされ、ASCII 形式で通信されるケースが多いようです。
コメント