文字コードとは 文字集合とは
英語のアルファベットや日本語のひらがな、カタカナ等、どのような文字が使えるかを示した文字リストを『文字集合 (character set , or charset)』と呼びます。
また、文字集合をどのようなビット列で表現するかを定義したものを『文字コード (character encoding)』と呼びます。
これら 2 つは厳密には意味が異なります。以下に例を示します。ASCII や Shift-JIS という文字コードは文字集合の意味も含まれていますが、Unicode は文字集合で、そのビット列表記を定義したものが UTF-8 や UTF-16 等になっています。
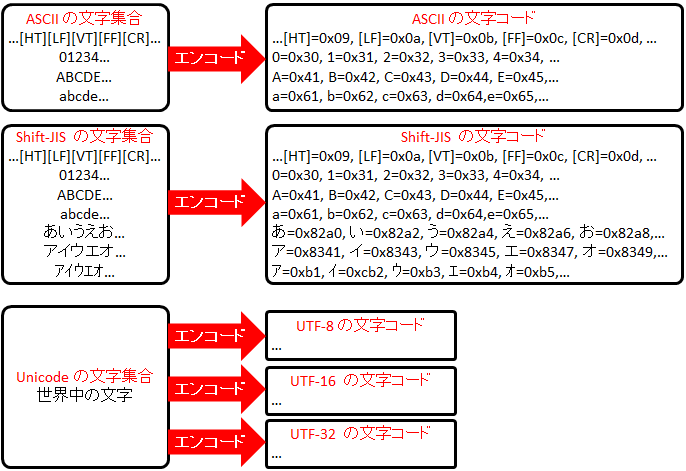
ただし、サーバのパラメータ等では charset = UTF-8 と書かれたりするように、charset (文字集合) と character encoding (文字コード) を同じ意味で使うこともあります。
文字コードの具体例として、例えばひらがなの『あ』という文字をファイルに保存するケースを考えます。Windows のメモ帳を使う場合、標準で Shift-JIS という文字コードが使われます。Shift-JIS で『あ』を表すのは 16 進数の『0x82a0』という 2 Byte のビット列ですのでこれがファイルに保存されます。
一方、CentOS (Linux) の vi や gedit を使って保存する場合は標準で UTF-8 が使われ、『あ』を表すのは 16 進数の『0xe38182』という 3 Byte のビット列です。
文字コードはその歴史から多くの考案が為されており網羅性をもって説明するのは困難です。なのでこの記事では Windows / Linux / Macintosh あたりでよく直面する問題に絞って解説してみます。
文字コードの基本 ASCIIのコード体系
文字コードの基本は『ASCII (アスキー)』です。これは主に英語のアルファベットの大文字小文字や数字(いわゆる英数字)といった印刷可能(人間が可読)文字に加え、改行に使われる CR(キャリッジリターン)や LF(ラインフィード)、タブを表す HT(水平タブ)等の印刷不可(人間が不可読)な制御文字で構成されています。
以下に ASCII のコード表を示します。

ASCII は一般的に 1 Byte = 8 bit 単位で扱われますが、実際には 7 bit だけで表現されます。範囲としては 16 進数で 00 - 7F ( 2 進数で 0000 0000 - 0111 1111)です。つまり先頭ビットは必ず 0 になるのです。
Windows標準のマルチバイト文字 [Shift-JIS] のコード体系とasciiとの互換性
1 文字 1 Byte で表現される ASCII コードに対し、その他のほとんどの文字コード (日本語やロシア語などの文字を表現する文字コード) は複数 Bytes で表現されます。
このような英語圏以外の文字を扱う文字コードを「マルチバイト文字コード」と呼びます。(それと対をなし、ASCII コードのことをシングルバイト文字コードと呼びます。)
Windows で日本語の文字を表現するときに標準で使われるのは前述の通り『Shift-JIS (シフトジス)』です。この文字コードは 1 Byte ~ 2 Bytes で表現され、また、ASCII コードとも互換性があります。
ではこれらの「1 Byte か 2Bytes か?」という可変長への対応や、 ASCII との互換性はどのように判別されているのでしょうか?
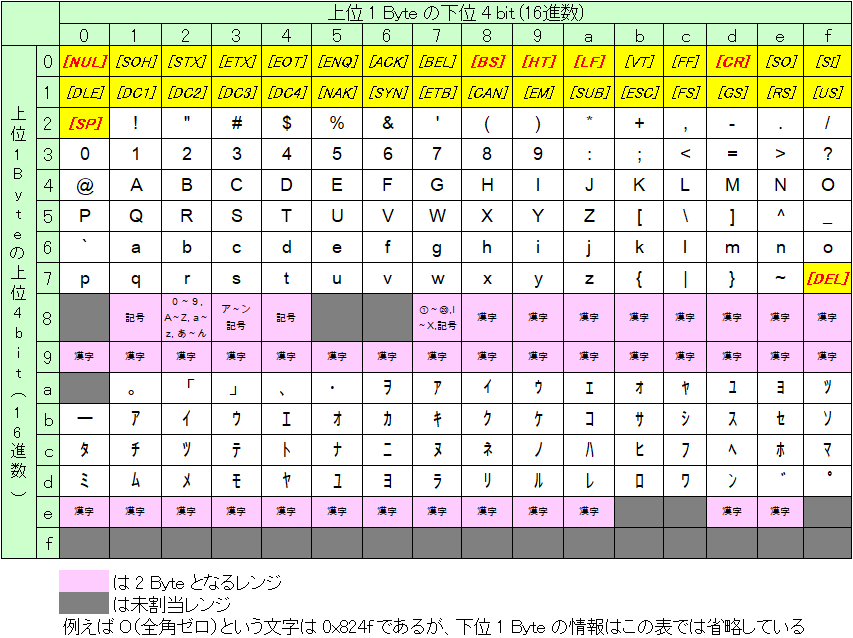
結論を言うと、最初の 1 Byte が 0x8, 0x9, 0xe の場合は次の Byte もセットで 2 Byte のコードであると判別し、それ以外の場合は 1 Byte のコードと判断します。さらに 0x00 - 0x7F の範囲は ASCII と Shift-JIS の内容が完全に一致していますので、これにより互換性が実現されます。
以下に Shift-JIS のコード表の概要を示します。ピンク塗り潰しが 2 Byte となるレンジです。また、グレー塗り潰しは未割当レンジです。
改行コードのバイト数
文字コードが『文字集合を bit 列化したもの』であるのに対し、改行コードは『どの制御コードが来たら改行と認識するか』という定義に過ぎません。
なので文字コードと改行コードは関係ありません。
Windows ではよく『0x0d0a』が使われます。0x0d は ASCII の制御文字 CR (キャリッジリターン), 0x0a は同じく制御文字の LF (ラインフィード) です。よく『CR+LF』や『CRLF』と表現されます。
なので Windows で改行すると、多くの場合は 2 バイトになります。
一方、Linux では『0x0a』が使われます。つまり LF (ラインフィード) のみで改行と見なすのです。『LF』や『LF only』と表現されます。
ゆえに Linux で改行すると、多くの場合は 1 バイトになります。
使われる改行コードは上述の『CR+LF』もしくは『LF』の 2 種類が多いです。ASCII と互換性のある文字コードはほぼ全て、このどちらかを改行コードとして使います。
Windows では CR+LF となるアプリケーションが多く、Linux / Macintosh では LF となるアプリケーションが多いです。(Macintosh は昔は CR only だったようですが。)
結果、Linux で作成したファイルを Windows の notepad で開こうとすると改行が全くされていない文章が開かれることがありますが、これが原因です。
ですが Windows でも例えば NoEditor というアプリケーションを使えば改行コードを自由に選択することができます。
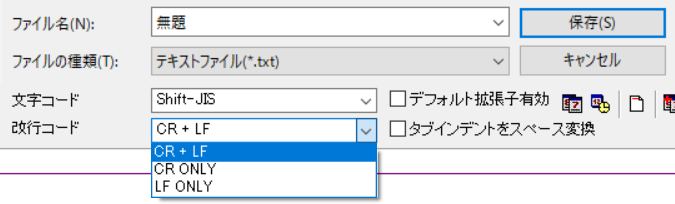
つまり、改行コードの扱いは(OSではなく)アプリケーションが決めるのです。(文字コードの扱いもそうですが。)
文字集合Unicodeと文字コードUTF-8の違いと関係性
ひと昔前では Shift-JIS のような ASCII と互換性のあるマルチバイト文字コードを、各国で独自に作ることが多く、色々なマルチバイト文字コードが乱立しました。結果、文字コード周りが複雑になり、文字化けの問題も多々見られるようになりました。
この問題を解消しようと策定されたのが Unicode です。
Unicode は文字集合ではあるのですが文字コードではありません。Unicode という文字集合をベースにどのようなエンコードを行うかを定めたのが『UTF-8』や『UTF-16』や『UTF-32』です。
具体的に言うと、Unicode では様々な国の文字に通番を振っただけです。採番は 0x000000 - 0x10FFFF の範囲なので 21 bit 分の情報が使われています。ただ、これをそのまま使うと良くないことが起きます。
まず、ASCII との互換性が無くなります。なぜならそのまま使うということは固定長で 21 bit (切り上げたら 3 Byte)を使うことになりますので、7 bit で表現される ASCII とは相いれません。
また、情報理論の観点から言うと、文字の利用頻度に極度の偏りがある場合、固定長は効率が悪いです。よく使う英数字(ASCII)が今までは 1 Byte だったのが 3 Byte に増えるわけですから、bit 消費が 3 倍になります。
そこで Unicode では採番 (文字集合) のみとし、エンコーディング( 文字コード) とは明確に分けたのです。Unicode の採番は 『U+####』(#は任意の番号) というような形式で表現されます。例えば日本語の『あ』は『U+3042』と表現されます。
現在の Linux 系では『UTF-8』という文字コードがよく使われます。Unicode からエンコードされ、ASCII との互換性を持った可変長 (1 Byte ~ 4 Byte) の文字コードです。
ASCII は当然の 1 Byte、ヨーロッパ系は 2 Byte、日本語等のアジア系は 3 Byte、その他特殊が 4 Byte です。
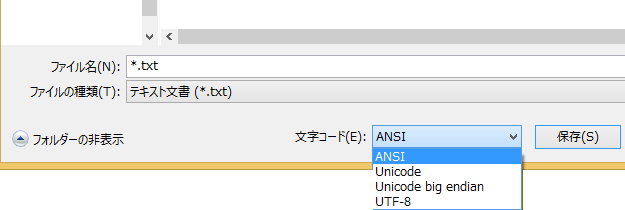
上記の話だけでも Unicode というのは誤解されやすいのですが、それに拍車をかけているものがいくつかあります。その 1 つとして、Windows では Unicode というと UTF-16 のことを指していたりします。notepad で『名前を付けて保存』をすると以下のように Unicode と表示されますが、これは UTF-16 を意味しています。
メールの文字コード (エンコード)
http や DNS の FQDN を始め、DHCP の client-id 等、様々なネットワークプロトコルでは文字列として ASCII コードを使っています。
SMTP もその 1 つです。SMTP では文字列を伝達する仕組みとして発展したため、原則 ASCII のみが使われます。メールヘッダやメール本文だけでなく、HELO のやり取りから全て ASCII です。
つまり、ASCII の範囲外である"先頭ビット 1" のバイトは使われる想定がありませんでした。(先頭ビットをどのように扱うかは受信するアプリのプログラミング次第。)
しかし時代が発展し、マルチバイト文字コードや添付ファイルの伝達をメールで行いたいというニーズが出てきました。そこで MIME (Multipurpose Internet Mail Extensions) という仕組みが出来ました。
仕組みとしては単純で、まずはメールヘッダ (宛先や件名などが載るフィールド) に以下 2 つの属性を付与するのみです。(メールヘッダも ASCII を使って "To:" や "Subject:" などと記述されます。)
- "Content-Type" : テキストなのか画像なのか exe なのか、といったファイル種別を示し、テキストであればさらに文字コードを示す。
- "Content-Transfer-Encoding" : ASCII 以外のバイト(つまり先頭ビットが 1 となるバイト)を ASCII に変換するエンコード方式を示す。
具体例として、以下のように示すと、UTF-8 のメール本文を、base64 という方式で ASCII に変換します。
Content-Transfer-Encoding: base64
base64 とは
base64 とは、任意のビット列を ASCII に変換するエンコード方式です。具体的には 3 Byte (= 24 bit) 分のビット列を 6 bit ずつ 4 つに分け、その 6 bit (= 64 通り) ごとに印刷可能文字を割り当てます。具体的なマッピング表は以下の通りです。
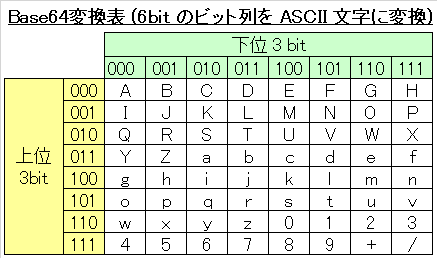
つまり 6 bit のビット列を ASCII の 1 Byte (= 8 bit) に変換することでこの問題を解決したのです。なお、ビット列末尾の 6 bit に満たない場合は 0 が補完されます。また、常に 4 文字がセットになりますが文字列が4の倍数にならない場合は = が補完されます。
例えば Shift-JIS で「あい」という文字列を base64 でエンコードする場合、まずは以下のように 2 進数に変換します。
い=0x82a2 -> 1000 0010 1010 0010
このビット列を繋げて 6 bit ずつに分割します。
末尾は 6 bit に満たないので 0000 を補完します。
これを Base64 変換表の通りに変換すると
最後に、4 文字単位にするため gqCC で 1 セットですが og には 2 文字足りないので == を補完します。なので
となります。これを 8 bit の ASCII として SMTP プロトコルに乗せ、通信先ではこれをデコードして元のビット列に復元するのです。
qp encoding とは
base64 以外にも qp ( quoted-printable ) encoding というものもよく使われます。ASCII が多い場合は qp の方が効率がよいですが、どちらも大差はありません。
ところで、メール本文は上記のやり方でいいとして、メールヘッダ内にある件名 (Subject) にマルチバイト文字コードを含める場合はどうするのでしょうか?
この場合は、"Subject: =?UTF-8?B?<encodeされた文字列>" というように UTF-8 と B (ase64) を示します。qp encoding を使う場合は B の代わりに Q になります。
コメント