Spectre/MeltDown の概要と影響範囲
2018/1/3 にCPUに関する脆弱性 Spectre (スペクター)/Meltdown (メルトダウン) が Google の "Project ZERO"によって公開され話題になっています。発見された脆弱性は 3 つ(Variant 1~3とラベルされています)で、うち2つが Spectre、1つが Meltdown に分類されます。
3 つとも CPU 性能向上のための「投機的実行 (Speculative Execution)」というコンセプトを実装した仕組み (Branch Prediction/Out of Order Execution) が原因だと判明しています。長い時間、予測を誤るように投機実行をさせ、その間にミスリードし、保護されたメモリ領域の読込や意図せぬプログラムの実行をさせるものです。
いずれの脆弱性もサイドチャネル攻撃に分類され、攻撃のための具体的な最低限の必要条件は Spectre は『攻撃対象のプログラムに不正なコードを埋め込み、実行させること』なのに対し、Meltdown は『攻撃対象の OS に一般ユーザ権限で不正なプログラムを実行させること』となっています。
つまり、いずれも「ネットワーク経由でサービスへ接続できる」だけでは不十分ですが、レンタルサーバや、IaaS/PaaS 等の他者が管理する VM を動かすクラウドサービスではその条件クリアは比較的容易であり、事業者等には大きなインパクトを与えているようです。
なお、Variant 1 および Variant 2 は Intel 製だけでなく、AMD および ARM 製の CPU でも脆弱性が確認されていますが、Varinat 3 については、Intel 製でのみ、確認できているようです。
ただし、いずれも具体的に脅威を及ぼす攻撃となるプログラムを構成するには、色々と細かい条件が必要です。今回の脆弱性発表はすぐさま影響があるわけではなく、あくまで『今後、この脆弱性を応用した、脅威となるプログラムウィルスが作られ得る』というレベルのように見えます。
関連: 2018/3/14 に AMD の CPU (Ryzen/EPYC) にも、Meltdown/Spectre とは別のクリティカルな脆弱性がある(MASTERKEY, RYZENFALL, FALLOUT, CHIMERA) とのレポートを、イスラエルの CTS-LAB 社が発表しました。私が内容を確認したところではクリティカルでもなんでも無いもののようにしか見えず、私以外にもそのような意見も多いようです。

脆弱性の仕組み理解のための基礎知識
投機的実行 (Speculative Execution) とは
OS 上でプログラムが実行されると、プログラムは最初に OS にメモリ領域を要求し、OS はそのプログラム用に要求通りのメモリ領域を与えます。メモリ領域内には『命令』と、『その命令に使うその他のデータ』が展開されます。
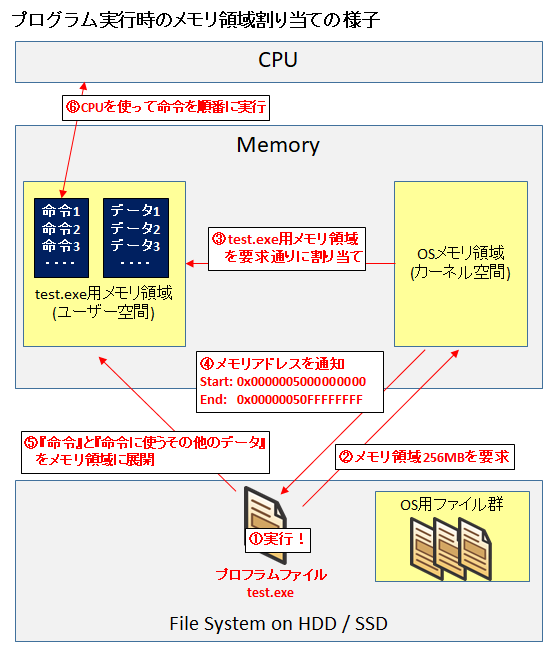
通常、CPU は命令を順番通りに実行していきます。命令を実行する際には、命令に必要なデータを、メインメモリからCPU 内のレジスタに読み込んでから命令を実行します。
ですが、現在の技術においては、CPU の速度に比べてメインメモリからレジスタへの読み込みがすこぶる遅いことがネックとなっています。
このボトルネック解消のためにキャッシュメモリがあります (L1/L2/L3等)。今後実行する命令を事前に読み込んだり、頻繁に使うデータを CPU 内のキャッシュメモリに貯め込むのです。これによりプログラム実行速度を速めることができます。
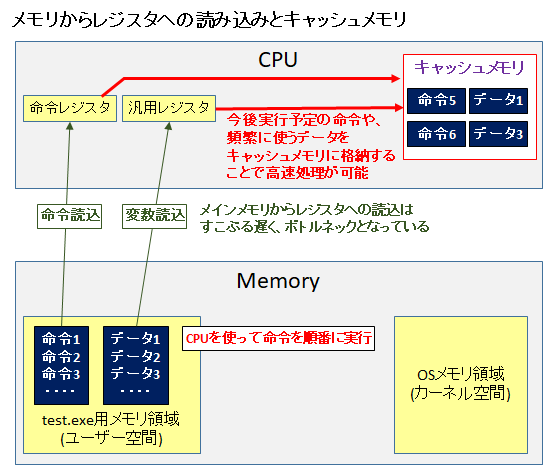
それとは別のアプローチでプログラム実行速度向上を目指したものがあります。それが投機実行です。
現在の標準的な CPU では、メインメモリからレジスタへデータを読み込むまでに、100 個以上の命令を出すことが可能ですが、命令は順番通りに実行しないと整合性が取れない可能性があるため、本来は次の命令や命令に使うデータを読み込むまで待機状態になります。
ですが投機的実行ではこのスタンスに異議を唱え、『その間 100 個以上の命令を何もせずに待機させるのはもったいない!データを読み込むまでの間にもできることをしようぜ!ダメだった場合はやり直せばいいじゃないか!』というスタンスで臨みます。
この「投機実行」は概念(考え方)であり、実装はいくつかあります。今回の脆弱性ではそのうち 2 つの実装が使われています。
1 つが「分岐予測」、もう 1 つが「アウト・オブ・オーダー実行」です。
分岐予測 (Branch Prediction) とは
分岐予測とは、if 文や switch 文、case 文によるプログラムの分岐において、分岐するかどうかを過去の履歴から予測し、予測結果が合っていれば分岐による待ち時間を無くすことができるという、投機的実行の実装例です。
分岐により待ち時間が発生するロジックの肝は、パイプラインにあります。
前述の通りメモリからレジストリへの読み込みが遅いため、命令は事前にどんどん先読みしてキャッシュします。
分岐予測をしない場合、if 文などの条件式の結果が確定するまでの間、次にどの命令を実行するかの結果を待つことになりますので、この先読みもしないままです。

ですが分岐予測をすることで、結果を待たずに、予測した分岐先の命令を (先読みを含め) どんどん先に進めて行くことができます。
また、図は概念理解のための簡易版なので表現されていませんが、(スマホはそうではないようですが、) 最近のサーバや PC に搭載される CPU は CISC アーキテクチャを採用しており、パイプラインが長いため、恩恵を受けやすいです (ただし、予測外れ時のペナルティも大きくなります)。
もし分岐予測が合っていれば、そのまま命令は進めます(投機のリターンとして実行速度向上が得られます)し、もし分岐予測が間違っていたとしたら、分岐予測直前の状態にロールバック (投機の代償として無駄に CPU を利用) し、従来の手順でプログラムを進めて行きます。
アウト・オブ・オーダー実行 (Out of Order Execution) とは
アウト・オブ・オーダー (Out of Order: O-o-O) の意味は、『順番通りでない』という意味です。通常プログラムはイン・オーダー (In Order)、つまり与えられた命令を順番通りにこなしていくものです。が、前述の通り、順番通りだと待ち時間が発生する可能性があります。
アウト・オブ・オーダー実行とは、もともとは投機実行の実装は無く、単純に「整合性に影響を与えない範囲でプログラムを先に実行していく」というものでした。
例えば以下のような命令の場合、
- c=a+b を実行せよ
- d=3+5 を実行せよ
- e=c+d を実行せよ
a と b がキャッシュメモリに無い場合、メインメモリから読み込むために時間がかかり、その間、命令 2 には手を付けられません。しかし命令 2 は命令 1 の結果には影響ないため、先に実施しても構いません。アウト・オブ・オーダー実行はこのようなケースに命令 2 を先に実施します。
ですがその性質から、投機実行と組み合わせて実装してみると相性が良さそうだと分かりました (1992 年には "An Out-of-Order Superscalar Processor with Speculative
Execution and Fast, Precise Interrupts" というタイトルの論文も発表されています)。
この組合せの実装では『整合性に影響を与えないかどうかは分からないけど、待ち時間はとにかく前に進んで、ダメだったら投機的実行直前の状態に戻ろう!』という動作をします。
今回の脆弱性のベースとなるアイディア
Project ZEROのページで、今回の脆弱性のベースとなるアイディアが以下のように掲載されています。

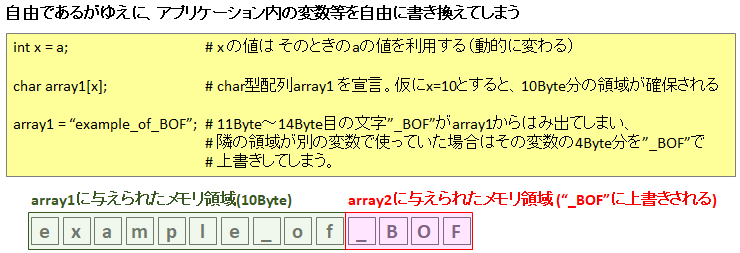
上記プログラムの緑で囲ったif文は、アプリケーションでメモリ保護 (Bounds Check) を行う際の一般的な記述方法です。arr1->data[]の配列には、その配列の大きさ (arr1->length) に応じたメモリが割り当てられますので、 "untrusted_offset_from_caller" が arr1->length よりも大きかったら、arr1 用に確保したメモリの外へ侵食してしまいます。これは場合によってはバッファオーバーフロー等の攻撃に使われる脆弱性になるので、この if 文でアプリケーション自身が自分で保護するわけです。
もし "arr1->length" がキャッシュメモリに存在しない場合は、分岐予測により紫で囲った命令を実行する可能性がありますが、その際は瞬間的に value はキャッシュに残りますが、arr1->length がメモリからレジスタへ読み込まれ、if 文での確認ではみ出していることが確認できた場合は速やかに value はキャッシュから破棄されます。
ところが以下のプログラムの場合は勝手が違います。
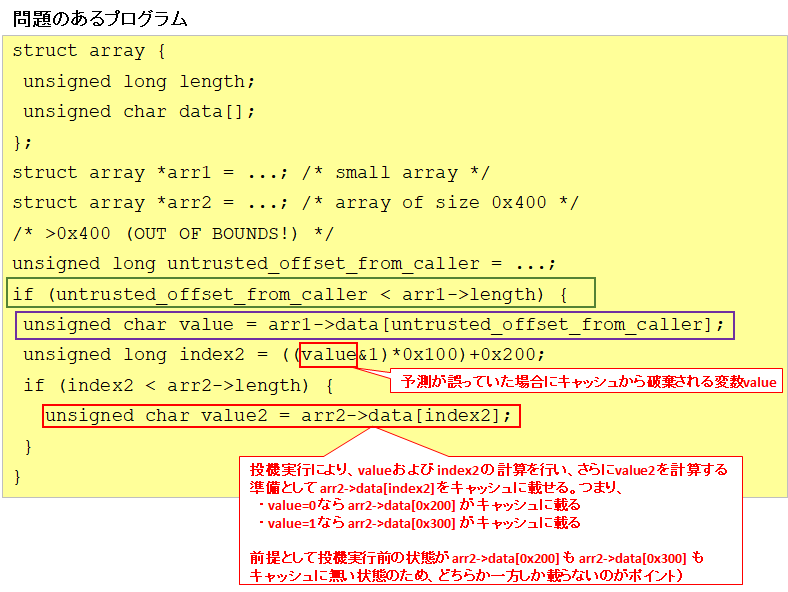
まず前提として、arr1->length 、arr2->data[0x200]、arr2->data[0x300] の 3 つがキャッシュされておらず、他の値がキャッシュされた状態だとします。
arr1->length がロードされ緑枠の if 文による分岐が確定する前に (つまり投機実行中に)、value および index2 を計算し、さらに value2 を計算する準備として arr2->data[0x200] もしくは arr2->data[0x300] のどちらかをキャッシュに載せます。つまり、value=0 ならば arr2->data[0x200] を載せるし、value=1 ならば arr2->data[0x300] をキャッシュに載せます。
そしてその後、arr2->data[0x200] と arr2->data[0x300] へのアクセスを試し、速いほうがキャッシュに載っているほうだと判断できますので 、これにより value が 0 なのか 1 なのかを判断できます。(この観測行為がサイドチャネル攻撃たる所以)
(『あ』さん、ご指摘ありがとうございます)
なお、前提条件の『3 つのデータがキャッシュされていない』という点については、攻撃プログラムの中にキャッシュを削除するプロセスを含めれば比較的容易にクリアできます。
このような『キャッシュを削除し、一定時間後にそのキャッシュがあるかどうかを時間計測により確認する』サイドチャネル攻撃手法はいくつかありますが、論文では『FLUSH+RELOAD』という手法を使っている旨が書かれています。
このあたりのサイドチャネル攻撃、およびそれに関連する『SpectrePrime/MeltdownPrime』については下記ページを参照して下さい。
脆弱性の概要
Variant 1: Bounds Check Bypass(CVE-2017-5753) の概要(Spectre-1)
CPU 性能向上のための仕組みである "Branch Prediction (分岐予測)" に起因する脆弱性です。
これについては前述のベースとなるアイディアとほぼ同じです。異なるのは、value=arr1->data[untrusted_offset_from_caller] が自身のアドレス範囲外 (つまり攻撃対象のメモリアドレス) を指定する点です。
Google の "Project ZERO" の具体的な攻撃例では、eBPF インタープリタ/JIT エンジン上で動作するスクリプト/プログラムを使っています。他の環境でも原理的には動作しますが、eBPF は Linux の様々なレイヤの動作をトレースする機能や、ユーザメモリ空間とカーネルメモリ空間を橋渡しするマップを保有することから、攻撃者にとっては一番コントロールし易い、というのが理由だそうです。
なお、普通に実行しても投機実行の時間が短いため、2 つのデータの一方をキャッシュする前に、分岐予測が外れたことを知り、ロールバックしてしまいます。なので、投機実行を長引かせるためには、ひと工夫が必要です。ここでは "Cache Line Bouncing" という事象をわざと引き起こし、予測外れを知る時間を遅らせています。
Variant 2: Branch Target Injection(CVE-2017-5715) の概要(Spectre-2)
こちらは Branch Prediction の実装例である "Indirect Call Predictor (間接分岐予測器)" に起因する脆弱性です。ただしこの脆弱性は CPU のマイクロアーキテクチャ実装に大きく依存するため、汎用的な攻撃は難しいようです。
Project ZERO は、Intel の CPU の間接分岐予測について、以下のことをリバースエンジニアリングで推定しました。
- 分岐元のメモリアドレスの内の 12bit を元に、分岐先のメモリアドレスを予測している
- Intel Hyper-Threading (ハイパースレッディング)を使って 1 つの物理コアを 2 つの論理コアに分割したとしても、2 つの論理コア間では間接分岐予測に使われる予測テーブル (BTB: Branch Target Buffer) は共有される
- 間接分岐の予測テーブルは、直近約 29 回分の履歴を元に、分岐先のメモリアドレスを予測している
これらの特性を悪用し、誤った分岐先メモリアドレスにある命令を投機実行をさせることができます。つまり 1 つの物理コアを分割した 2 つの論理コアを、それぞれ異なる VM に割り当て、片方の VM で偏った分岐を行い作成した予測テーブルを、もう片方の VM でうまく参照させるようにします。その際、予測に使う 12 bit が同じであるが、それ以外のアドレスが異なるメモリアドレスから不正な命令へ飛ぶようにプログラムを配置しておき、不正な命令を投機実行させるのです。
Google の "Project ZERO" は具体的な攻撃例を示し、成功率は 99% だったと言っていますが、その条件は『KVM 上の VM 2 台を利用し、Intel Hyper-Threading を利用した上で、同一物理コア 1 つを 2 つの論理コアに分割したものをそれぞれ専用に割り当てる』、『VM 2 台とも ASLR (Address Space Layout Randomization:プログラムの位置を予測しづらくし、バッファオーバーフロー等の攻撃を失敗させやすくする。最近の OS ではデフォルト有効。) を無効化する』、『2 台の VM で、同一の悪意あるプログラムを同一メモリアドレスで走らせる』、『そのプログラムは、[CLFLUSH] 命令でキャッシュをフラッシュ (消滅) させ、間接分岐予測で誤って実行させるような前フリの条件分岐を 26 回繰り返し置き、ループ実行させる』といった現実離れした環境下での話です。
Variant2 は ROP (Return Oriented Programming) のモデルをヒントにしています。ROP はスタックバッファオーバーフロー攻撃からの防御策をさらにすり抜けるための、脆弱性発見手法 (概念) です。ROP では『ガジェット』と呼ばれる関数が呼び出し元から戻る (Return) 際に脆弱性があれば、そのガジェットを利用して攻撃を仕掛けます。
間接分岐は主に関数が呼び出し元へ戻る際の分岐で使われることが多く、ROP のテーマには沿っています。そして Variant2 では ROP とは異なり、ガジェット自体に脆弱性があるかどうかは問題ではありません。ガジェットの戻りの間接分岐の予測を誤らせ、意図しないコマンドを投機実行し、キャッシュに痕跡を残すのです。
Variant 3: Rogue Data Cache Load(CVE-2017-5754)の概要(Meltdown)
CPU 性能向上のための仕組みである "Out of Order Execution (アウト・オブ・オーダー実行)" に起因する脆弱性 (厳密に言うと、アウト・オブ・オーダー実行と投機実行の両方を実装している CPU で発生する脆弱性) で、ユーザ空間にあるプロセスが、本来アクセスできないはずのカーネル空間のメモリ領域の情報をサイドチャネルで観測できてしまいます。
仕組み的には Variant 1 と似ていますが、単純な話にすると、
- ユーザ権限実行プログラムからカーネルメモリアドレスを読み込む命令
- 1で読み込んだデータを使って別計算
というプログラムを実行したとします。
1 では違反 (ユーザ権限ではカーネルメモリアドレスは読み込めない) が出るため、その例外処理を行うための処理が走りつつも、裏ではアウト・オブ・オーダー実行により 2 が動作しています。1 がデータをロードし、それが例外処理を経て違反と確定する間に、2 を実行し、その結果を別の形でキャッシュに保管します。そしてその結果から、カーネルメモリアドレスの値を逆算します。
簡単に書いていますが、実際には『1 のロード < 2の実行 < 1の違反確定』という時系列を成立させるのは難しいです。なので通常はこの条件だけでは攻撃は成立しないのですが、特定条件下の特定実装においてはすり抜けられるようです。
Google Project Zero のページでは、アイディアの1つとして『違反の例外処理を故意に長引かせるようにしてはどうか』といった考察がされています。
Meltdown と Spectre の違いをより深く知りたい方は、以下に分かり易く理解できる記事を作りましたので、併せてご参照下さい。
コメント
説明間違ってます。
value2は分岐ミスしてるほうのパスに含まれているので、値はレジスタに書かれないし、ましてメモリにストアされません。したがって後でその値を確認することは無理です。
肝は、分岐ミスしてるパスでもキャッシュのリプレースは発生するので、valueの値に応じたキャッシュラインがリプレースされることです。valueが0ならarr2->data+0x200がリプレースされるし、valueが1ならarr2->data+0x300がキャッシュに乗ります。したがって、後でどちらのキャッシュラインが乗ったのかを、メモリにアクセスして時間計測することで(キャッシュに乗ってれば早い)、valueの値が分かるという仕組みです。
詳細な説明ありがとうございます。本記事大変興味深く拝見させていただきました。
一点ご質問がありますので、不躾で申し訳ございませんが、コメントを残させていただきます。
記事の具体例の中に
if (index length) { … }
とありますが、これは本脆弱性を付く意味で必須なのでしょうか?
1つ目の分岐に関しては、投機実行をキックする意味で必須なのはわかるのですが、2つめの分岐に関しては、配列境界確認は作法として当たり前だよね、という意味で追加してある分岐という認識で正しいでしょうか?それともキャッシュに載せるための条件として何か意図があるのでしょうか?
ご返信いただければ幸いです。
まぐさん
コメントありがとうございます。
私も正直理解に迷ったところですが^^; キャッシュに載せる条件では無いと認識しました。ただし、それは私のCPUやこの攻撃に対する理解がベースではなく、Google Project Zeroのページの記載内容を素直に読むと、という意味です。
私も『キャッシュに残すためには別の分岐予測等が必要なのでは?』とも考えたのですが、特にそのような記述はありませんでした。また、arr2->lengthに関する説明も一切ありません。(強いて言えば、「arr2->length=0x400であり、キャッシュされている状態とする」だということが暗に表現されていますが)
今回の攻撃は「分岐予測」が誤ったことを知る前にキャッシュ読み込みをしなければならないので余計なif文はむしろ無いほうがよいはずなのですが、それでもこれを付けた理由は「arr1->length をチェックしているのにarr2->lengthのチェックが無いのはコードとして不自然」というくらいのものではないでしょうか。
ご返信ありがとうございます。
納得しました。
今後も記事更新、頑張ってください!