この記事は CentOS8.2 で確認しています。
top コマンドの見方
top コマンドは CPU/メモリの利用状態を全体、および各プロセスごとに確認することができます。
例えば以下のように表示されます。表示は 3 秒ごとに更新されます。
top - 00:47:32 up 2:37, 2 users, load average: 3.01, 1.52, 0.47 Tasks: 118 total, 2 running, 116 sleeping, 0 stopped, 0 zombie %Cpu(s): 12.5 us, 6.9 sy, 0.0 ni, 99.7 id, 0.3 wa, 0.0 hi, 0.0 si, 0.0 st MiB Mem : 3736.1 total, 297.6 free, 235.2 used, 3203.3 buff/cache MiB Swap: 820.0 total, 812.5 free, 7.5 used. 3267.1 avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 1 root 20 0 179396 13800 8672 S 0.0 0.4 0:01.10 systemd 2 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kthreadd 3 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 rcu_gp 4 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 rcu_par_gp 6 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 kworker/0:0H-kblockd 9 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 mm_percpu_wq 10 root 20 0 0 0 0 S 0.0 0.0 0:00.21 ksoftirqd/0 ~~~~~
top - 00:47:32 up 2:37, 2 users,
00:47:32 は時刻を示しています。自分の時計とずれていたら、日本時間じゃない可能性や時刻同期ができていない可能性があります。
up 2:37 は OS が起動してから 2 時間 37 分経過したことを示しています。
2 users は 2 ユーザが (SSH などで) コンソールへログインしていることを示しています。
load average: 3.01, 1.52, 0.47
load average は多くの場合「ディスク IO 待ちのプロセス数」を示しています。(厳密にはこれに加え「実行中のプロセス数」) (2022.3.31 M.Hotta 様のコメントご指摘を反映)
つまり、単位は [個] です。
左から順に [ 1 分平均], [ 5 分平均], [ 15 分平均] の数値です。この数値が高いとパフォーマンスに影響を及ぼしていると考えられます。
load average は Linux のパフォーマンスを見るときによく観察される指標です。
load average の見方、考え方の詳細は後述「load average の見方と目安、CPU使用率との比較」に示します。
Tasks: 118 total, 2 running, 116 sleeping, 0 stopped, 0 zombie
現在、118 個のプロセスが存在し、2 個の実行中のプロセスがあり、116 個のスリープ中のプロセスがある、ということを示しています。
stopped は Ctrl + Z 等で実行を停止されたプロセス数、zombie は「子プロセス自身は終了するつもりなのに、親プロセスからそれを承認する wait() システムコールが戻ってこない」プロセス数を指します。
%Cpu(s): 12.5 us, 6.9 sy, 0.0 ni, 99.7 id, 0.3 wa, 0.0 hi, 0.0 si, 0.0 st
top の 2 行目は、プロセスを [us, sy, ni, id, wa, hi, si, st ] というカテゴリに分類し、前回表示から今回表示までの間の (つまりデフォルトでは 3 秒ごとに表示更新なので 3 秒間の) 各カテゴリでの実行時間のパーセンテージを示しています。
カテゴリの定義は以下の通りです。
- us : un-niced なユーザ空間プロセス (OS 上で動作するように作られたプログラム) が実行された時間のパーセンテージ
- sy : カーネル空間プロセス (OS としての機能を司るプログラム) が実行された時間のパーセンテージ
- ni : nice や renice 等により nice 値が変更されたユーザ空間プロセスが実行された時間のパーセンテージ (つまり、nice により狙い通りに優先的に動作しているかを確認することができる)
- id : idle 状態を過ごしたプロセスの時間のパーセンテージ
- wa : Disk IO が終わるのを待っているプロセスの実行時間のパーセンテージ
- hi : ハードウェア割込みの時間のパーセンテージ
- si : ソフトウェア割込みの時間のパーセンテージ
- st : ハイパーバイザに徴収された実行時間のパーセンテージ
Linux では特定プロセスの優先度を上げる場合に、nice コマンドを使ってプロセスを起動します。これによりそのプロセスの「nice 値」が変わり、他のプロセスよりも優先的に CPU 処理の時間が多く割り当てられます。
un-niced というのはそのような優先をしていない、デフォルトで起動したユーザ空間プロセスです。
ハードウェア割込みとソフトウェア割込みについては、本記事の最後に軽めに解説します。
st は、VMware ESXi や KVM, Microsoft Hyper-V 等のハイパーバイザ上の仮想マシンで Linux を動作させているときに、Linux 上では CPU を使える状態なのに、ハイパーバイザ側から利用を断られた時間を示しています。
特に CPU をオーバーコミットした状態では、他の仮想マシンが高負荷の際に CPU を取り合いになりますので、この値が大きくなります。
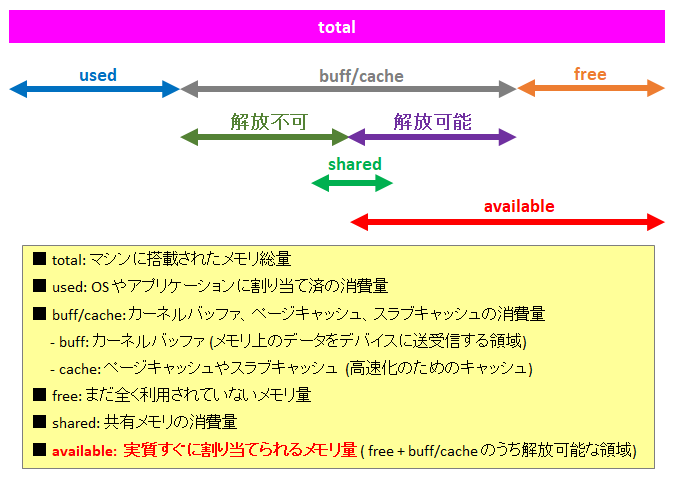
MiB Mem : 3736.1 total, 297.6 free, 235.2 used, 3203.3 buff/cache
MiB Swap: 820.0 total, 812.5 free, 7.5 used. 3267.1 avail Mem
1行目。物理メモリの総量 (total) が 3736.1 MiB、空きのメモリ (free) が 297.6 MiB、OS やアプリケーションに割り当て済のメモリ量 (used) が 235.2 MiB、バッファやキャッシュに割り当て中のメモリ量 (buff/cache) が 3203.3 MiB となります。
2行目。同様に SWAP 領域の総量 (total) が 820.0 MiB、空き (free) が 812.5 MiB、OS やアプリケーションに割り当て済 (used) が 7.5 MiB であることを示しています。
ただし、最後の 3276.1 avail Mem については SWAP 領域ではなく、物理メモリの話になっています。これは物理メモリの実質的な空き容量が 3267.1 MiB であることを示しています。
メモリ使用率の見方や考え方は後述「メモリ使用率の見方、考え方」に示します。
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
- PID : プロセス ID (プロセスの識別子)。
- USER : 実行ユーザ。
- PR : Priority。低いほど優先される。rt となっている場合は real-time (つまり最優先) で実行されている。
- NI : nice 値のこと。低いほど優先される。rt の場合を除き、NI = PR - 20。
- VIRT : 割当済の仮想メモリ容量 (KiB)。スワップも含む。
- RES : Resident Memory Size (KiB)。スワップを含まない、物理メモリのうち、実際に消費されているメモリ容量。
- SHR : Shared Memory Size (KiB)。RES のうち、共有メモリとして消費されているメモリ容量。
- S : Process State Code。詳細は「プロセスの State Code (状態コード)」にて後述。
- %CPU : CPU で処理を行った総時間のうち、そのプロセスが処理を行った時間の割合。つまり、列で総和を取ると 100 になる。前回表示から今回表示までの間 (デフォルト 3 秒間) で計測される。
- %MEM : 物理メモリの容量に対する、RES (実際の消費メモリ容量) の割合。つまり、列で総和を取ると 100 になる。
- TIME+ : プロセスが起動してから、CPU により処理された総時間。+ は 10 ミリ秒単位で表示していることを示す。
- COMMAND : 実行プロセス名。ユーザ空間プロセスの場合は実行ファイル名が表示され、カーネルスレッドの場合はカーネルスレッド名 (kworker/0:2-events 等) が表示される。
メモリ使用率の見方、考え方
メモリの 2 行について、ヘッダ (total, free, used, buff/cache, avail Mem) のそれぞれの関係は下図の通りです。
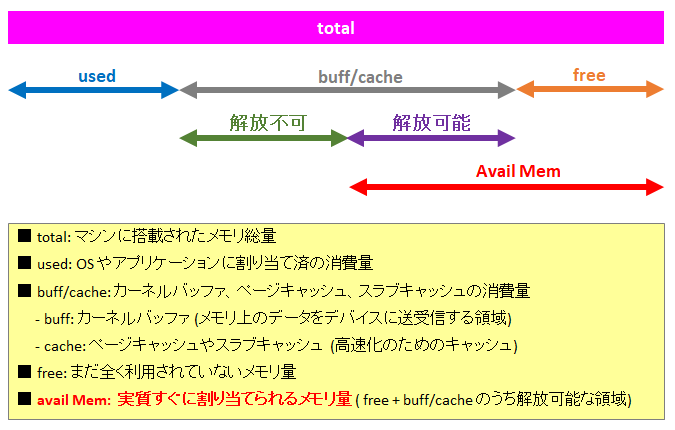
このコマンドで、メモリの空き状況を確認したいのであれば、free を見るよりも avail Mem を見ましょう。
なお、2 行目の SWAP については total, free, used のみが表示されています。buff/cache や Avail Mem の概念はありません。
load average の見方と目安、CPU使用率との比較
load average は障害切り分け時にもよく使われますが、目安というのは難しいです。というのも、単なる高負荷なのかバグ起因の障害なのかの判別が難しいからです。
ちょっとの負荷をかけただけなのに、10 を超えるのであればプログラムに問題があると考えられますが、本番環境で 200 を超えていたとしても「ただ負荷が掛かっているだけ」なのか「プログラムに問題があるのか」というは load average だけで判断できません。
なので、この場合はあくまで状態の参考情報程度で考えたほうがよいでしょう。
では、load average の示す数字は具体的にどのようなものでしょうか。
load average は /proc/loadavg から情報を引っ張ってきています。/proc 配下の情報は man proc でマニュアルページを表示できます。そこには以下のように書かれています。
/proc/loadavg
The first three fields in this file are load average figures giving the number of jobs in the run queue (state R) or waiting for disk I/O (state D) averaged over 1, 5, and 15 minutes. They are the same as the load average numbers given by uptime(1) and other programs. The fourth field consists of two numbers separated by a slash (/). The first of these is the number of currently runnable kernel scheduling entities (processes, threads). The value after the slash is the number of kernel scheduling entities that currently exist on the system. The fifth field is the PID of the process that was most recently created on the system.
プロセスの State Code が R (running) もしくは D (waiting for disk I/O) の状態のプロセス数である、とのことです。
CPU の使用率は 100% 張り付きの状態だと問題ですが、90% あたりを推移しているのであれば、「CPU を実に有効に活用している」という解釈もできます。
一方、load average が高い状態というのは「プロセスからディスクへの書き込みが積滞している」状態を示していることが多く、一般的なボトルネックの箇所なので着目し工夫すべき点です。
プロセスの State Code (状態コード)
プロセスの State Code の定義は man top でも確認できますが、man ps のほうが詳細に書かれています。以下、man ps の抜粋。
PROCESS STATE CODES
Here are the different values that the s, stat and state output specifiers
(header "STAT" or "S") will display to describe the state of a process:
D uninterruptible sleep (usually IO)
I Idle kernel thread
R running or runnable (on run queue)
S interruptible sleep (waiting for an event to complete)
T stopped by job control signal
t stopped by debugger during the tracing
W paging (not valid since the 2.6.xx kernel)
X dead (should never be seen)
Z defunct ("zombie") process, terminated but not reaped by its parentハードウェア割り込みとソフトウェア割り込み
ハードウェア割り込みは、物理的な電気信号を使って CPU に割り込みを要求し、最優先で処理をしてもらう仕組みです。主にデバイスの制御に使われます。
具体的にはキーボードの入力や DMA (Direct Memory Access) 等に使われます。
一方、ソフトウェア割り込みは、プログラミングの記述によって CPU に割り込みを要求します。
具体的にはシステムコール利用時 (ユーザモードからカーネルモードへ移行するための割り込み) や例外 (ゼロ除算など) などで使われます。
コメント
とても有益な情報ありがとうございます。
今までtopコマンドの見方がいまいち掴めていなかったのですが、この記事のおかげでスッキリすることができました。
se 様
コメントありがとうございます。お役に立てたようで何よりです。
今後も本サイトを宜しくお願い致します。
有用な情報をありがとうございます。
記事の中で『load average は「ディスク IO 待ちのプロセス数」を示しています。』と言い切ってしまっているところがちょっと気になりました。
これは記事内でも触れられているように、『number of jobs in the run queue (state R) or waiting for disk I/O (state D) 』なので、たとえ D State のものがなくても、たとえば stress コマンドで CPU 負荷をかけるだけで(≒無限ループするプロセスが多くても) load average の数値は上がります。初心者の方の参考になるサイトだと思いますので、『多くの場合』を入れるなど、少し表現を和らげていただくことをご検討いただけますと幸いです。
M.Hotta さん、コメントご指摘ありがとうございます。
このような有益なツッコミを初心者向けという点も汲んで頂いた上でマイルドに頂けるのは非常にありがたいです。
先輩から学んだ言葉をそのまま書いておりましたが、たしかに仰る通りですので、ご提案の通りに修正させていただきました。
今後も本サイトを宜しくお願い致します。
有益な情報ありがとうございます。
PR、NIについて確認させてください。
記事中では「高いほど優先される」とありますが、「低いほど優先される」ではないでしょうか?
お手隙の際にご確認頂けますと幸いです。
sato さん、コメントありがとうございます!
ご指摘の通り、「低いほど優先」が正解でした。。。
$ man top より
NI -- Nice Value The nice value of the task. A negative nice value means higher priority, whereas a positive nice value means lower priority. Zero in this field simply means priority will not be adjusted in determining a task's dispatch-ability.修正させていただきました。
今後も本サイトを宜しくお願い致します!