セクターサイズとブロックサイズ(クラスタサイズ)の違い
セクターサイズと Advanced Format について
セクターサイズはHDDの物理的な作りに依存するものです。昔は 512 Byte(バイト) の HDD が主流でしたが、今は 4KB のものが増えてきています。他のデバイスの高速化、および扱うデータの大容量化に伴い、パフォーマンス向上のためにはセクタサイズは大きくした方がよいからです。
ですが、セクターサイズ 4KByte の HDD を使うには、OS 側でもそれをサポートしなければなりません。そこで過渡期である現在、4KB と 512 Byte の両方に成りすませる [ Advanced Format ] の HDD が流通しています。OS が 512 Byte しかサポートしていない場合は "512e"(e=エミュレーション)というモードで動作し、物理セクターサイズ=4KBなのに論理セクターサイズ=512 Byte として OS から見たらあたかも 512 Byte であるかのように振舞います。
Linux では fdisk -l で見た時に以下のようになります。
Sector size (logical/physical): 512 bytes / 4096 bytes
なお、SSD にはセクターという物理要素はありませんが、Advanced Format と同様、論理セクター(製品によっては仮想セクターと呼ぶ)を提供できますし、ものによっては設定でセクターサイズを変更できます。
クラスターサイズ(ブロックサイズ)について
一方、クラスターサイズやブロックサイズは、ファイルシステムに依存するもので、ファイルシステム上の領域を扱う最小単位を意味します。つまり、ファイルシステムに読み書きする場合は必ず 4KB 単位で読み出し/書き込みを行うのです。
HDD へのアクセスはセクターサイズですので、セクターサイズの整数倍にしないと非効率になります。例えば極端な例でセクターサイズが 512 Byte でブロックサイズが 513 Byte だと、ファイルシステムへの読み書き時において 2 セクターの 1024 Byte 分へアクセスし、511 Byte 分を無駄に捨ててしまうことになります。
Windows では標準的には『クラスタサイズ』は4KByteです。『クラスタサイズ』を確認するには、コマンドプロンプトを管理者権限で起動し、fsutil fsinfo ntfsinfo を実行します。
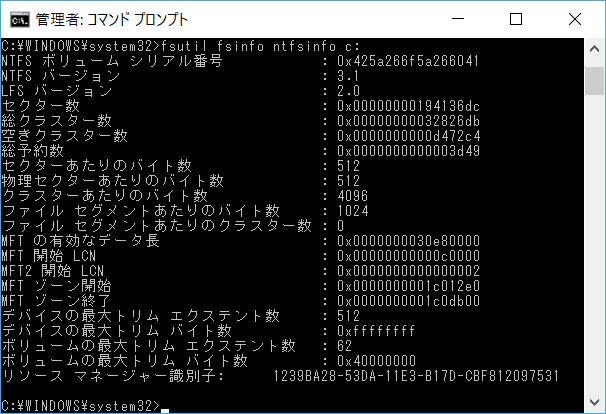
この例では『クラスターあたりのバイト数』が 4096 (=4KB) となってます。
また Linux については、現在の RedHat 系の一般的なセッティングでは XFS のデフォルトの『ブロックサイズ』は 4KB となります(変更可)。ファイルシステムは HDD や SSD へのデータ配置をブロック番号で指定します。ブロック番号は 64bit で指定されますので、ブロックサイズが 4KB の場合は理論上、2^64 (2の64乗) * 4KB = 約64ゼッタバイトまで表現可能です。
XFS ファイルシステムでブロックサイズを確認するには xfs_info コマンドを使います。
[root@localhost ~]# df
ファイルシス 1K-ブロック 使用 使用可 使用% マウント位置
/dev/mapper/centos-root 19056640 1112112 17944528 6% /
~~~
[root@localhost ~]# xfs_info /dev/mapper/centos-root
meta-data=/dev/mapper/centos-root isize=512 agcount=4, agsize=1191680 blks
= sectsz=512 attr=2, projid32bit=1
= crc=1 finobt=0 spinodes=0
data = bsize=4096 blocks=4766720, imaxpct=25
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=1
log =internal bsize=4096 blocks=2560, version=2
= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0上記の例の場合、"data =" の横にある bsize がブロックサイズです。4096=4KB であることが分かります。またブロック数は blocks= にある通り、4766720 ブロックです。4KB と掛け算をすると約 20GB ですので、約 20GB の HDD を使っていることが分かります。
不良セクターとファイルシステムチェック(Linux)/チェックディスク(Windows)について
不良セクターについて
不良セクターとは、HDD の物理的な不具合のことです。HDD はセクター単位で取り扱いますので、どんなに局所的な故障でもセクター毎切り捨てます。よくある誤解として、不良セクターを「修復・回復」するという表現が使われることがありますが、実際には不良セクターの故障を直しているのではなく、故障を見込んであらかじめ用意してある替わりのセクター(代替セクターと呼びます)を割り当て、OS が故障セクターへアクセスしようとした際に代替セクターへ誘導するようセッティングされるのです。
当然、代替セクターには限界がありますので、故障数が多くなると修復ができなくなります。
RAID5 + HotSpare と RAID6 の比較
また、不良セクターについては1つ厄介な問題があります。それは、実際にアクセスしてみないと故障しているかどうか分からないことです。つまり、故障時すぐに気づくことは稀であり、故障した後に幾分か時間が経ち実際にアクセスしてうまく読み取り/書き込みができないと判明したタイミングで、ようやく不良セクター認定および修復が行われるのです。
chkdsk には「不良セクタをスキャンし、回復する」というオプションがありますが、これはこれまでの記載の通り、スキャンしないと不良セクタという識別ができないのであり、また回復というのもハード故障を直すのではなく代替セクターを割り当てる作業になります。
RAID6 が登場した背景も実はこの問題が関連しています。RAID5 + HotSpare で稼働中の RAID グループが、あるディスクアクセスの時に故障を検知し、HotSpare の HDD を使ってリビルドし始めたタイミングで、以前から内在していた別の HDD での故障が見つかり修復不能になるケースが問題視され、この解決策として RAID6 が登場したのです。
ファイルシステムチェック/チェックディスクについて
ファイルシステムチェック(Linux の fsck や xfs_repair)やチェックディスク(Windows の chkdsk コマンド)の主たる目的はファイルシステムの論理的な不具合を調べることであり、物理的な不具合を調べることはオプション的要素です。
これらのチェックは、例えば OS が稼働中に突然ダウンしてしまい HDD への処理途中で終わってしまった場合等に起こりえるファイルシステム上の不整合を確認します。
例えばある 1 つのブロックが複数のファイルから割り当て、参照されているような状態など、ファイルシステム内の様々な矛盾を検知します。
その性質上、HDD の全てのセクターへアクセスしますので、その中でうまく読み込めないセクターがあったらそれを不良セクターとして認識します。このチェックコマンドのオプションによっては、不良セクターの修復までやってくれます。

コメント