Overview and scope of influence of Specter / MeltDown
The CPU vulnerabilities, Spectre/Meltdown, are published on Google's "Project ZERO" on January 3 2018, which is a hot topic. The vulnerabilities discovered are three (labeled Variant 1 to 3), two of which are classified as Spectre and one is classified as Meltdown.
It has been found that all three are caused by a mechanism of "Branch Prediction" & "Out of Order Execution" that implements the concept of "Speculative Execution" for improving CPU performance. This attack leads CPU the speculative execution with wrong prediction for a long time, in the meantime, reading of a protected memory area , or executing unintended programs.
Both vulnerabilities are classified as Side-Channel Attacks. Specific minimum requirement for spectre attack is that "Malicious program (or script) has been embeded on the target program, and the code is executed" and one for meltdown attack is that "Malicious program is executed with user privilege on the target OS".
In other words, it is not enough to just connect to the service via the network. But in the cloud service that runs VMs managed by others, such as rental servers and IaaS / PaaS, it is relatively easy to clear the conditions, which seems to have a major impact on business operators.
In Variant 1 and Variant 2, not only Intel, but also CPUs of AMD and ARM are vulnerable, but Varinat 3 seems to be confirmed only with Intel.
However, in order to compose a program that becomes an attack that exerts a specific threat in any way, various detailed conditions are necessary. This vulnerability announcement does not have an immediate effect, and it seems to be a level of "to be able to create a threatening program virus applying this vulnerability" to the last.
Basic knowledge for understanding mechanism of the vulnerabilities
What is Speculative Execution?
When the program is executed on the OS, the program first requests the memory area to OS, and OS gives the requested memory area for that program. "Instruction" and "Other data used for that instruction" are loaded in the memory area.
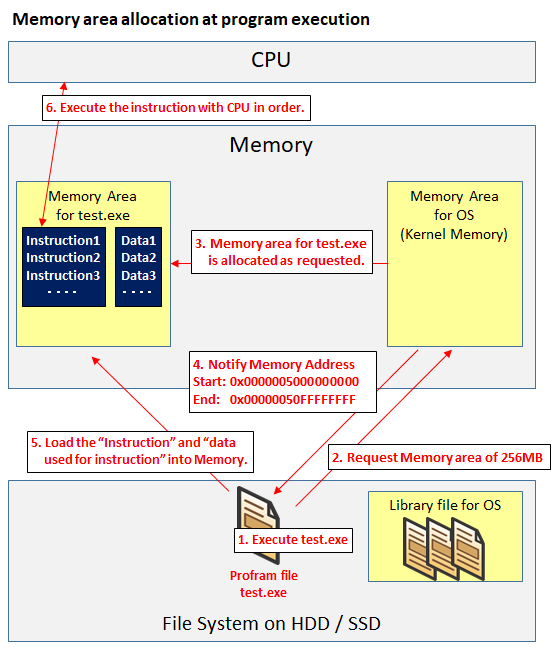
Normally, the CPU will execute instructions in order. When executing an instruction, it is necessary to read the datas for the instruction from the main memory to the register in the CPU before executing the instruction.
However, in current technology, it is a bottleneck that reading from the main memory to the register is extremely slow compared to the speed of the CPU calculation speed.
To eliminate the bottleneck, there is a cache memory(L1 / L2 / L3 etc). We store frequently used data in the cache memory in the CPU. This speeds up the program execution.
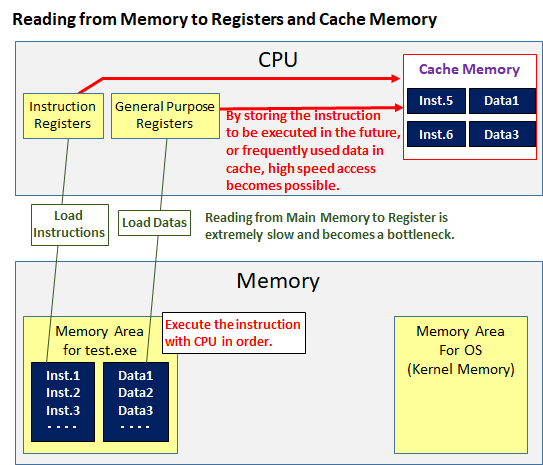
There is another approach that aims at improving program execution speed by a different approach. That is Speculative Execution.
With the current standard CPU, it is possible to issue more than 100 instructions before reading data from the main memory to the register, but since there is a possibility that consistency can not be obtained unless instructions are executed in order, it will wait until it reads data to be used for the next instruction or instruction itself.
However, in speculative execution, we objected to this stance. We will face it with the stance that "In the meantime it is a waste to have more than 100 orders waiting without doing anything! Let's do what you can do before you read the data! If it was useless it should be done again!
This "Speculative Execution" is a concept, and there are several implementations. Two of these implementations are used in these vulnerabilities' attacks.
One is "Branch Prediction" and the other is "Out-of-Order Execution".
What is Branch Prediction
Branch Prediction is implmentation of Speculative Execution, and means predicting from the past history whether or not to branch by "if", or "switch", or "case" statement in a program, and if the prediction result matches, it is possible to eliminate waiting time.
The point of the logic that causes the waiting time at branch is the "pipeline".
If Branch Prediction is not performed, until the result of the conditional expression such as "if" statement is confirmed, it will wait for the result of which instruction to execute next. Even if data used for conditional expression is not in the cache memory it will be kept waiting for a long time.

However, by implementing the Branch Prediction, you can advance the predicted branch destination instruction (including reading data from main memory) more quickly without waiting for the result.
In addition, although the figure is not expressed because it makes simple for understanding concepts, recent CPUs of servers and PCs (not about Intelligent Phone), adopt the CISC architecture and the pipelines are long, so it is easy to get the benefit (although the penalty at the time of unexpectedness also increases).
If the Branch Prediction matches, the instruction will proceed as it is (the execution speed is improved as a speculative return), and if the branch prediction was wrong, roll back to the state just before branch prediction (price of speculation We will spend the CPU as uselessly) and proceed with the program in the conventional procedure.
What is Out of Order Execution?
The meaning of Out of Order (O-o-O) means "not in order". Normally, programs are in order (In Order), that is, they execute the given instructions in order. However, as mentioned above, there is a possibility that waiting time will occur if it is in order.
Out-of-order Execution originally had no implementation of speculative execution, and it was simply to " execute the program first in a range that does not affect consistency".
For example, in the case of the following instruction,
- Perform c = a + b
- Perform d = 3 + 5
- Execute e = c + d
If a and b are not in the cache memory, it takes time to read from main memory, while instruction 2 can not be handled.However, since instruction 2 has no effect on the result of instruction 1, it can be executed earlier.Out-of-order execution first executes instruction 2 in such a case.
However, because of its nature, it turned out that compatibility seems to be good when implemented in combination with speculative execution (In 1992, "An Out-of-Order Superscalar Processor with Speculative
Execution and Fast, Precise Interrupts" has also been published).
In the implementation of this combination, we will try with following attitude, " I do not know if it does not affect consistency, but while the wait time goes ahead anyway and if it's no good, we will return to the state just before the speculative execution! .
The idea as the base of this vulnerability
On the Project ZERO page , the idea as the base of this vulnerability is posted as follows.

The if statement enclosed in green in the above program is a general description method when memory protection (Bounds Check) is performed in the application.Since arr1->data[] array is allocated memory according to the size (arr1->length) of the array, if "untrusted_offset_from_caller" is larger than arr1->length, it will run out of secured memory I will excuse you. So I protect with this if statement.
If "arr1->length" does not exist in the cache memory, there is a possibility of executing an instruction enclosed in purple by branch prediction, but in that case the value is instantaneously left in the cache, but arr1-> If length is read from the memory to the register and it can be confirmed that the confirmation by the if statement confirmed, the value is promptly discarded from the cache.
However, in the case of the following program, selfishness is different.
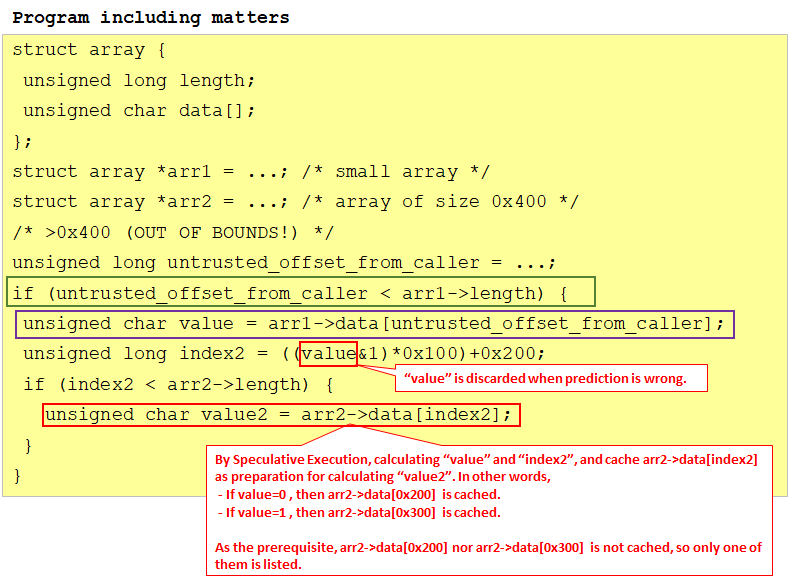
First of all, it is assumed that three of arr1->length, arr2->data [0x200], arr2->data[0x300] are not cached and other values are cached.
Before arr1->length is loaded and the branch by the if statement in the green frame is finalized (ie. during speculative execution), calculate value and index2, and moreover, cache either arr2->data[0x200] or arr2->data[0x300]. That is, if value = 0, put arr2->data[0x200], and if value = 1, put arr2->data[0x300] in the cache.
After that, you can try accessing arr2->data[0x200] and arr2->data[0x300], and you can judge that the faster one is in the cache, so that whether value is 0 or 1.
As for the point that "3 data is not cached" in the precondition, it is relatively easy to clear by including the process of deleting the cache in the attack program. Such a side channel attack method that deletes the cache and confirms the existence of the cache after a certain time by time measurement is called "FLULSH + RELOAD".
Overview of vulnerability
Variant 1: Outline of Bounds Check Bypass (CVE-2017-5753) (Spectre-1)
It is a vulnerability caused by " Branch Prediction " which is a mechanism for improving CPU performance.
Originally, the application allocates a memory area at startup, protects it by using the application so that memory is used within that range (that is, it does not access outside the range of the given memory area).The application mentioned here also includes the OS.
This memory protection is generally called Bounds Check (memory boundary check), but in this attack, let's make a misprediction that Bounds Check is "no problem" by branch prediction and before we learn that prediction is out, You can make data calls from memory outside the boundary from malicious applications and save them in the L1D cache.
Normally, if branch prediction is lost, it rolls back to the state before speculative execution, but before that, it executes another calculation using that data and stores it in a different cache area.From the calculation result, if you keep the value of the original data to be known, you can know the state of the memory outside the range.
Even if it is executed normally, it knows that the branch prediction has gone off before doing another calculation, and rolls back, so you need to make some effort.We will delay the time to learn about misdeeds by the method "Cache Line Bouncing".
In the specific attack example of Google's "Project ZERO", we use a script / program that runs on the eBPF interpreter / JIT engine.Although it operates in principle in other environments, it seems to be the reason that it is easiest for attackers to control.
Variant 2: Outline of Branch Target Injection (CVE - 2017 - 5715) (Spectre - 2)
This is a vulnerability caused by "Indirect Call Predictor (Indirect Branch Predictor)" which is an implementation example of Branch Prediction. However, as this vulnerability depends heavily on CPU micro-architecture implementation, it seems that general-purpose attacks are difficult.
Project ZERO estimated with reverse engineering that "The Indirect Branch Prediction of Intel's CPU predicts the branch destination address from the some 12 bits in the branch source memory address" and, "Even if you divide it into two logical cores by using Intel Hyper-Threading, the prediction table used for Indirect Branch Prediction is shared on a physical core."
By exploiting these characteristics, it is possible to speculatively execute an instruction at the wrong branch target memory address.In other words, two logical cores divided from one physical core are allocated to different VMs, and one VM predicts the prediction table created by unbalanced branching in one VM so that it can be referred to successfully by the other VM.At that time, 12 bits to be used for prediction are the same , but placing the program so that the other addresses jump from different memory addresses to illegal instructions, speculatively execute illegal instructions.
Google's "Project ZERO" shows a concrete example of attack and said that the success rate was 99%, but the condition is "using two VMs on KVM, using Intel Hyper-Threading, Dedicated assignment of one identical physical core divided into two logical cores "," Invalidate ASLR for both VMs "," Run the same malicious program with the same memory address in two VMs "The program is a story in an unexpected environment such as" to clear the cache with the [CLFLUSH] instruction, place a multiple branch (26 branches) that causes indirect branch prediction to execute, and execute the loop".
Variant 3: Outline of Rogue Data Cache Load (CVE-2017-5754) (Meltdown)
A vulnerability caused by "Out of Order Execution" which is a mechanism for improving CPU performance makes it possible to access a memory area that should not be accessed.Strictly speaking, it is a vulnerability that occurs in CPUs that implement both out-of-order execution and speculative execution.
It is structurally similar to Variant 1, but in a simple story,
- An instruction to read the kernel memory address from the user authority execution program
- Calculated separately using data read in 1
Suppose you have run the program.
1, although violation (kernel memory address can not be read with user authority) appears, 2 behaves by out-of-order execution behind.1 loads the data and executes 2 and stores the result in a separate cache while it is determined to be a violation.Then, from the result, inverse the value of the kernel memory address.
It is easy to write, but in fact it is difficult to establish a time series of "1 load <2 violation".Usually, attacks are not established only by this condition, but seems to be able to pass through in specific implementations under specific conditions.
Next: Essential difference between Spectre & Meltdown

コメント